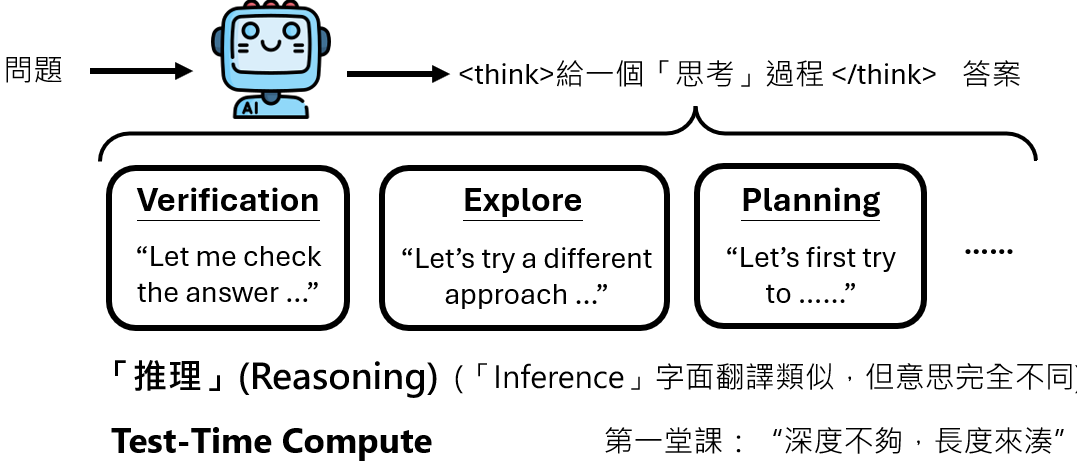
深度思考Reasoning
模型深度固定,通过让模型思考长度变长,可以提高模型的准确度,使模型生成中间的推理过程(对复杂问题尤为有效)。具体方法有COT、给模型推理流程、模仿学习有reasoning功能的模型以及RL。
但是也不是越长越好,有时候可能会过犹不及,结果不一定越来越好,反而还消耗很多资源,特别是对于简单的问题。
Reasoning过程:
verification 是否正确
explore 有没有别的方法
尝试计划
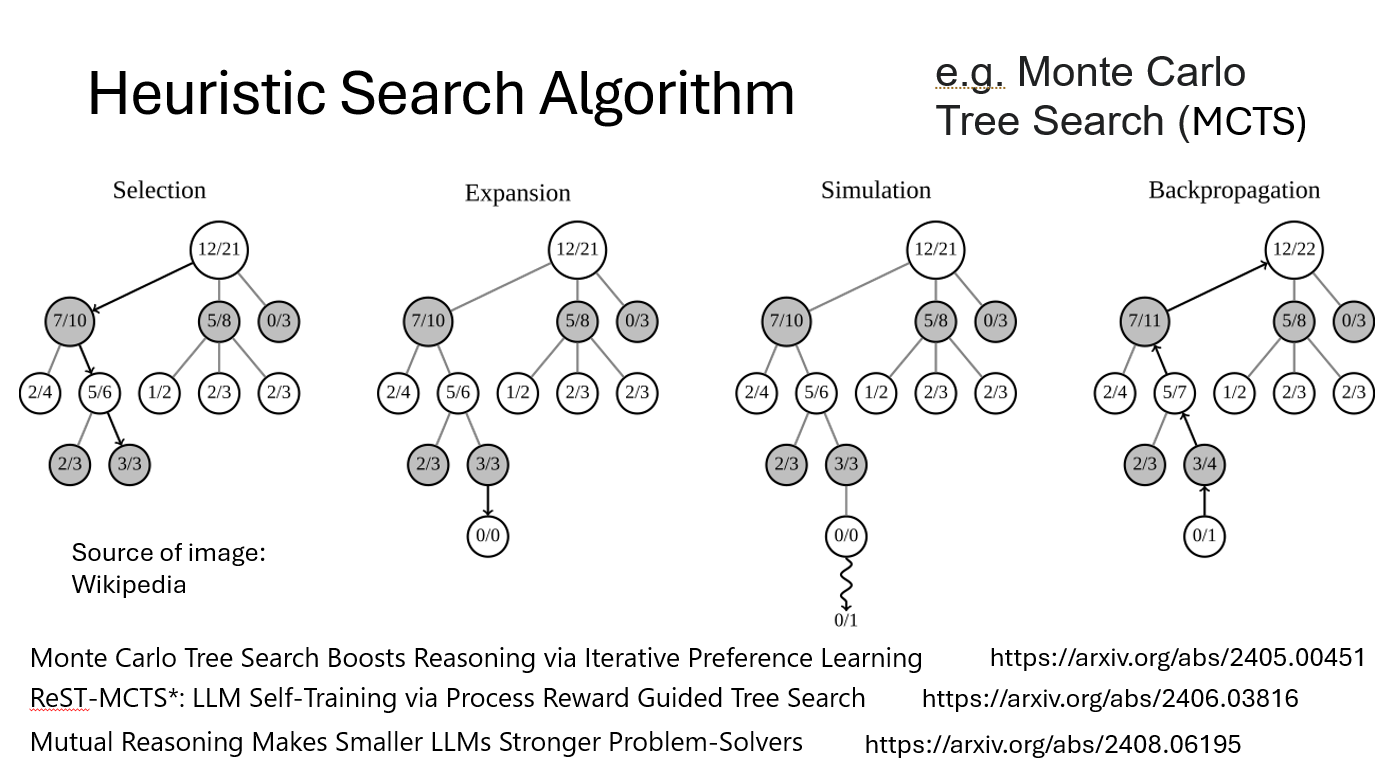
“Monte Carlo tree search”,即蒙特卡洛树搜索。它是一种启发式搜索算法

CoT
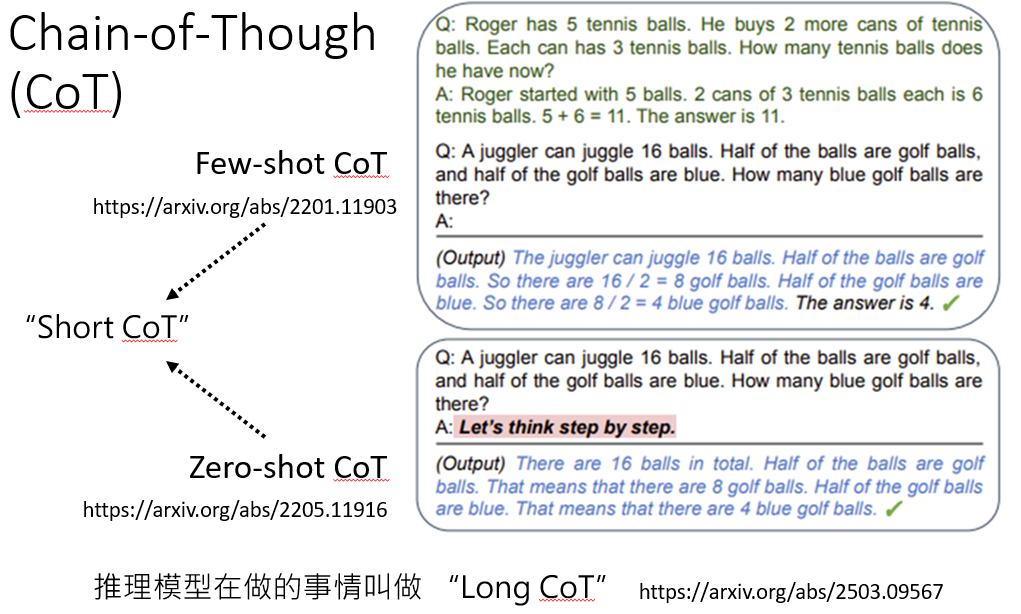
告诉模型如何“think step by step”
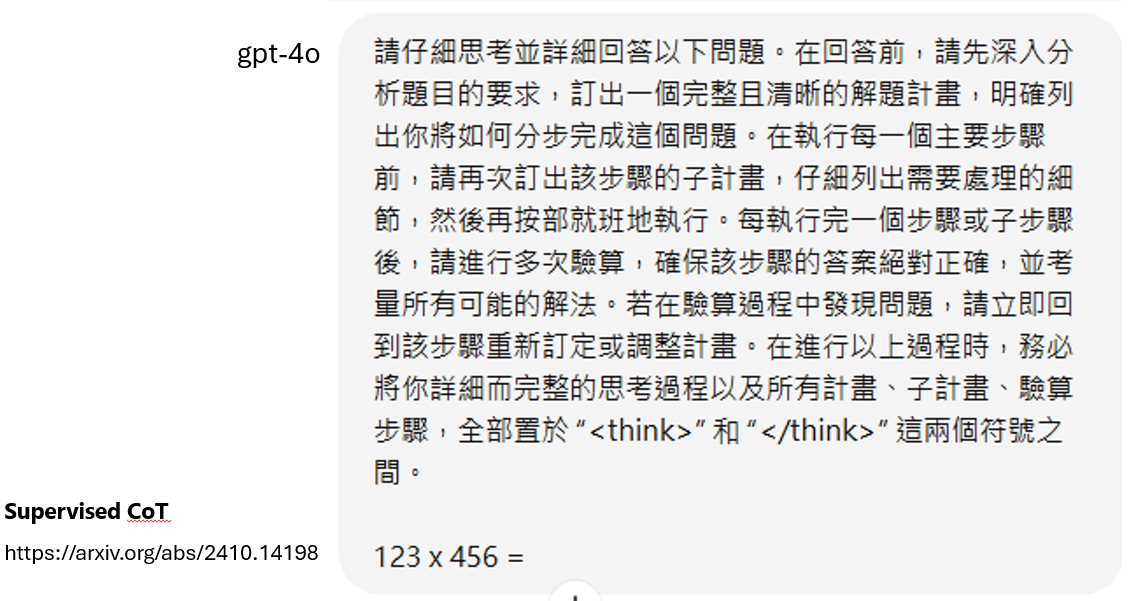
但是只适用于能力比较强的模型, 能力弱的模型没有办法读懂根据Supervised CoT生成正确的思考过程
给模型推理流程
愚者千虑,终有一得
让模型回答次数足够多, 总会有一次(太弱的模型也不行)得到正确答案

如何知道哪个是正确答案?
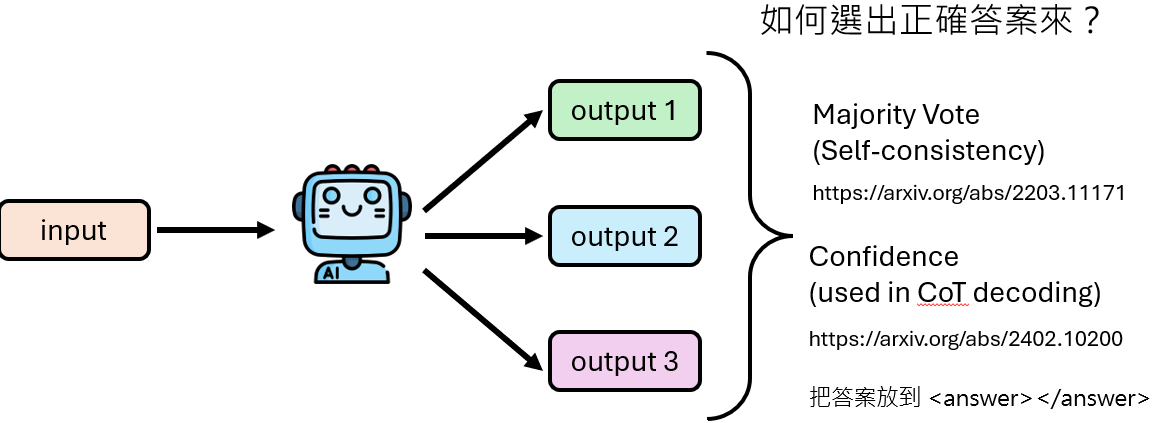
Majority Vote
对多次生成的答案进行投票
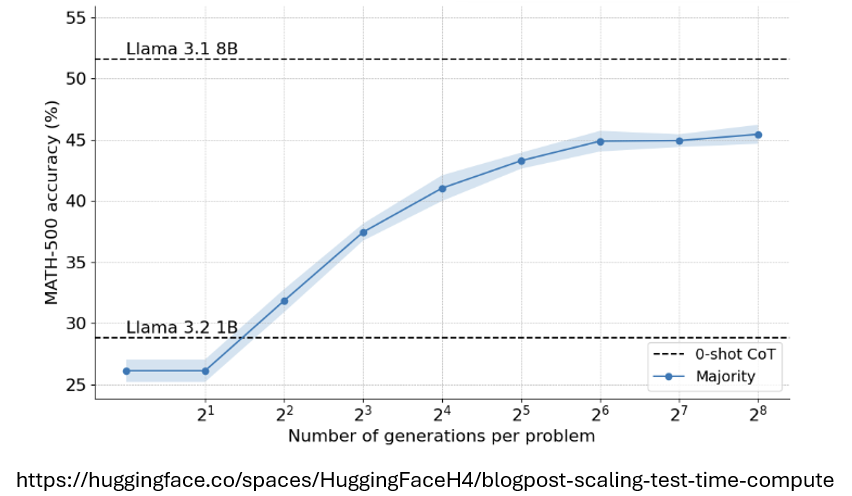
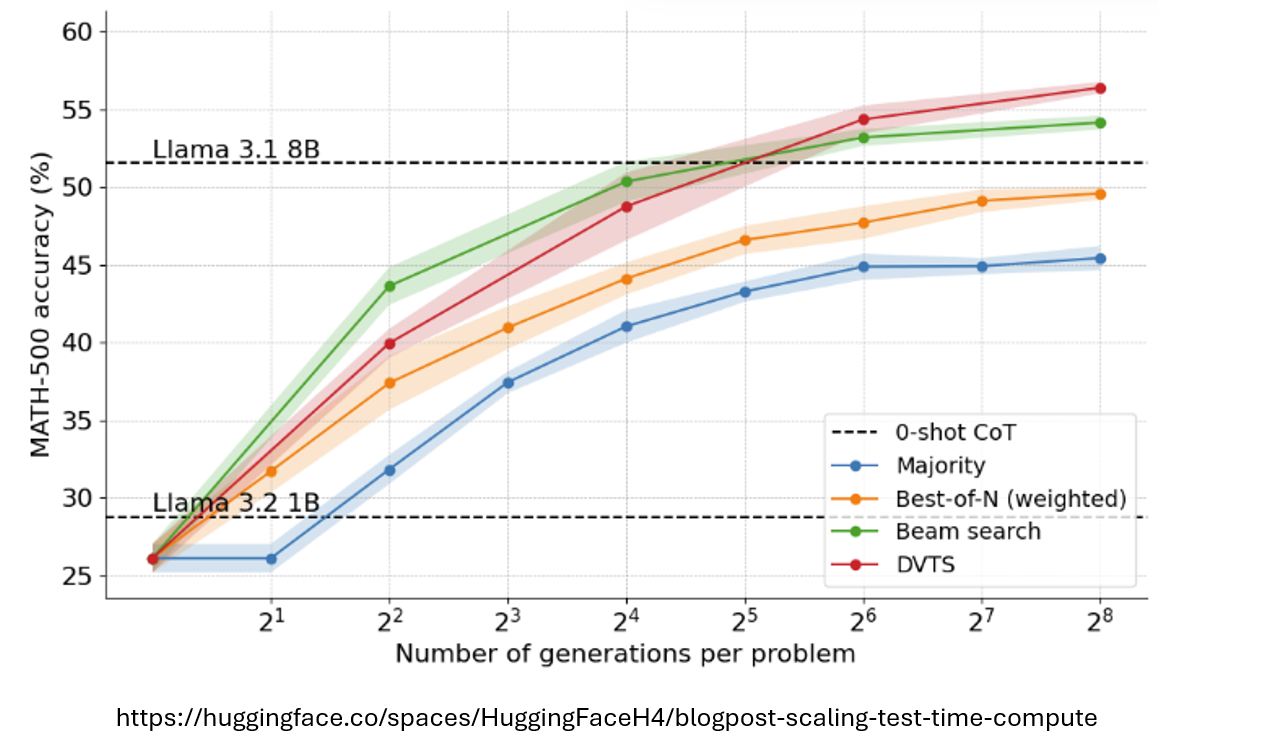
Llama 1B在多次生成答案后进行Majority Vote 的结果明显好于原始模型
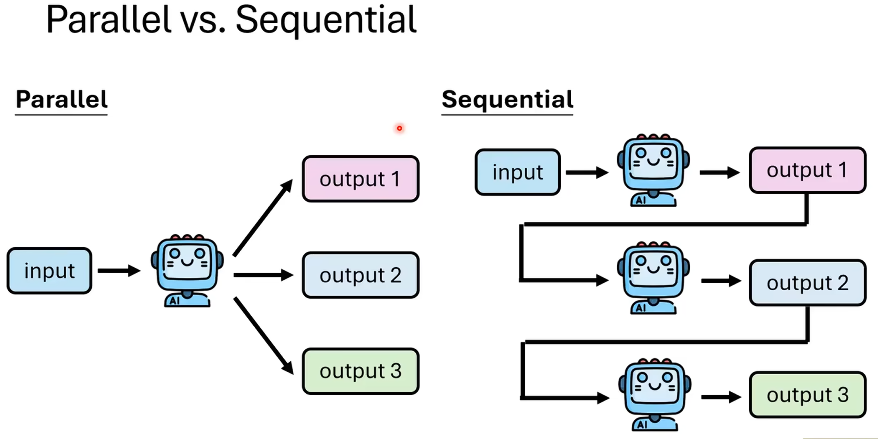
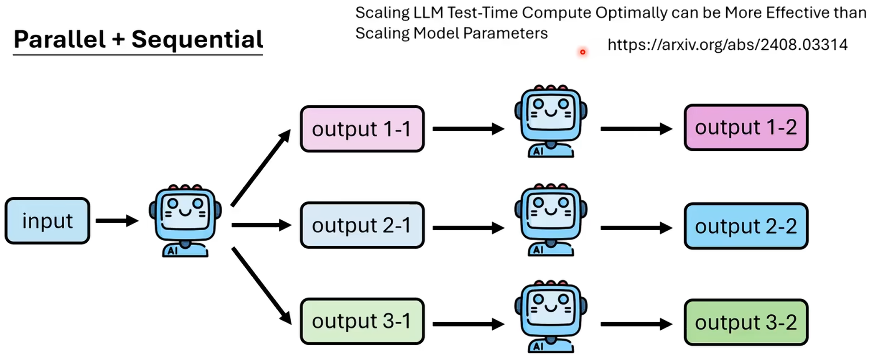
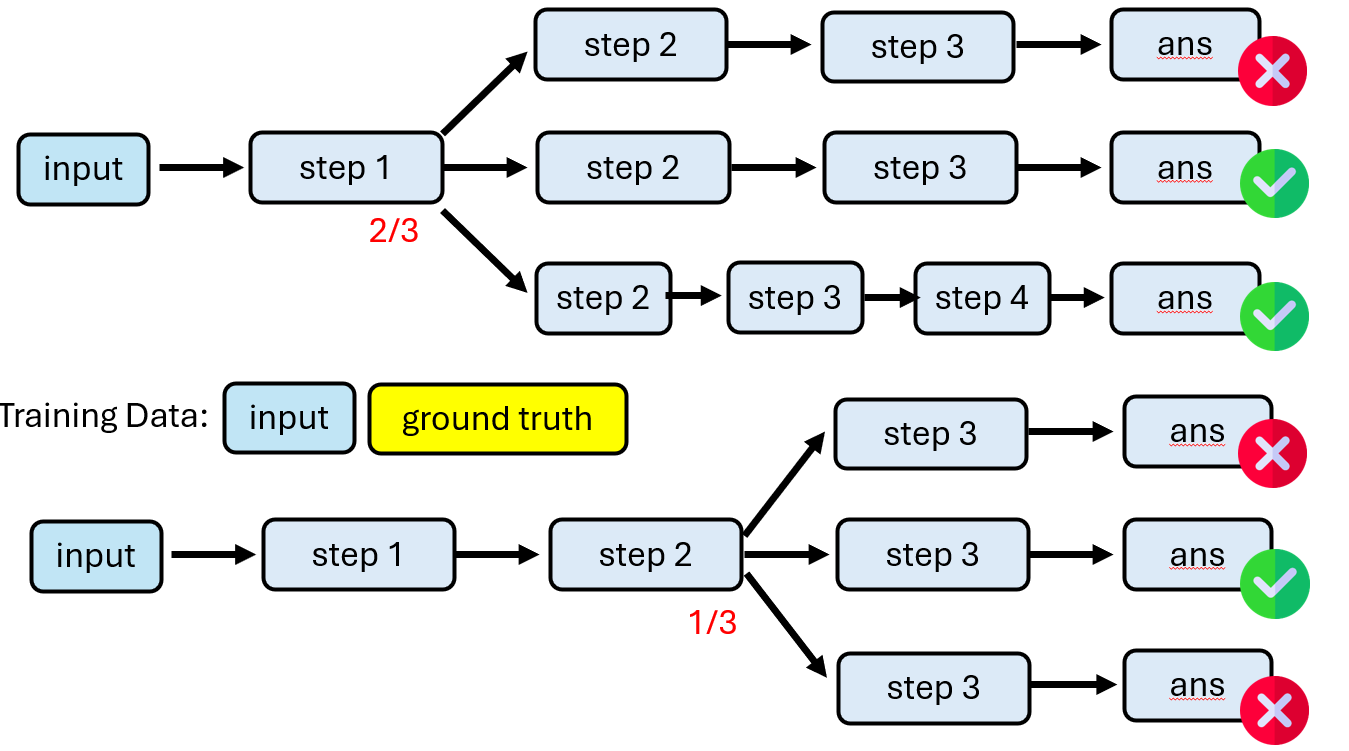
我们需要对逐步推理过程中的每一步进行验证,这样防止浪费
如何实现每一步都进行verify
每一个步骤都用<step> </step> 包裹,遇到 </step> 后就验证,使用Process Verifier
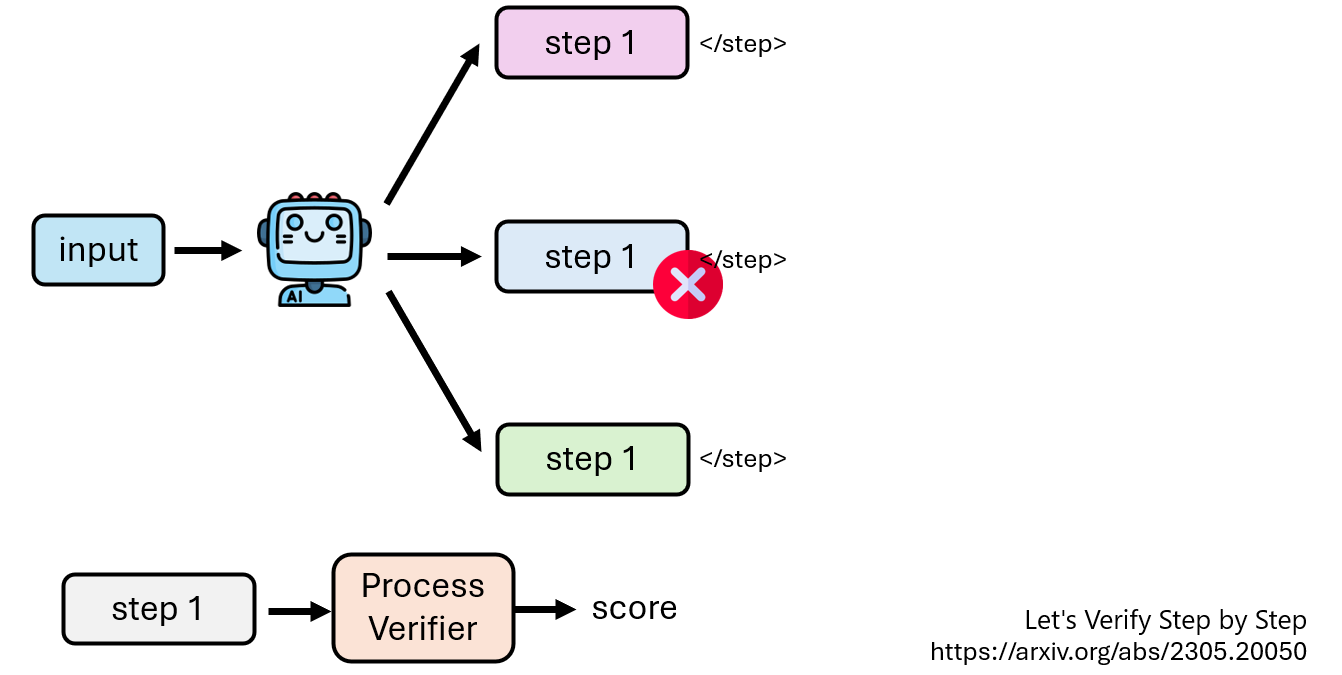
但是我们只有问题和正确答案,如何去判定这个step的正确与否呢?
把这个step后所有的可能都生成出来,得到最后所有的结果正确的比例or回答结果质量的好坏,后面Process Verifier再次遇到这样的step就会知道当前step的好坏并进行评分
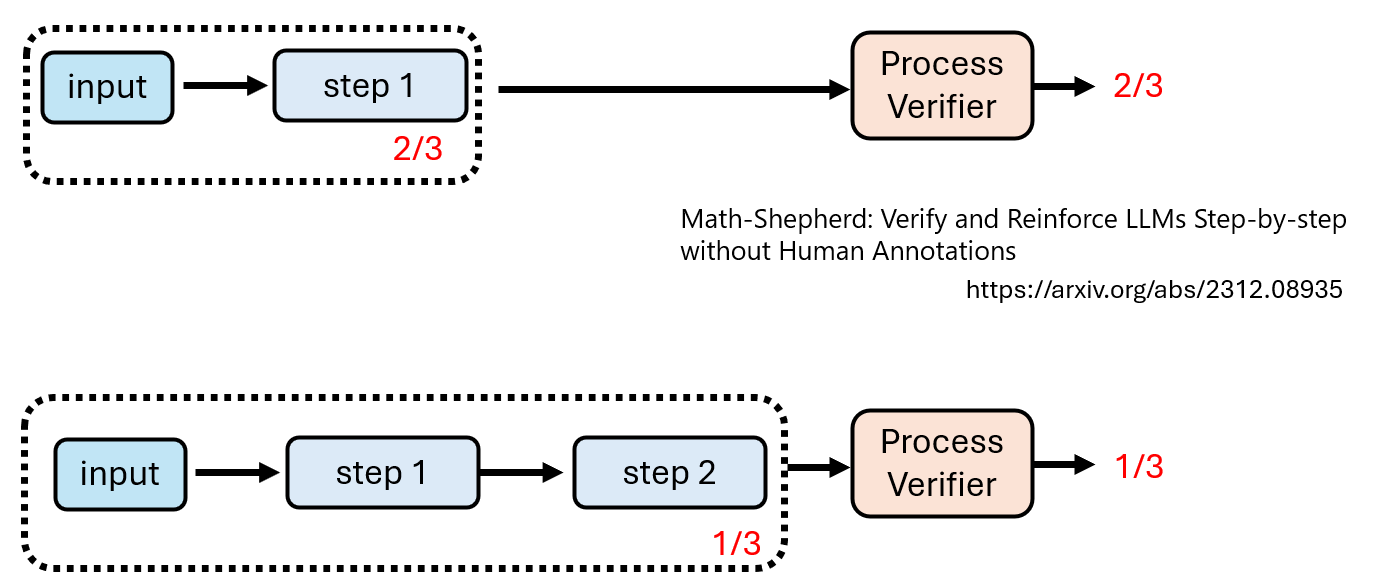
Process Verifier输出的分数如何界定好坏?
Beam Search : 每次只保留N条路径
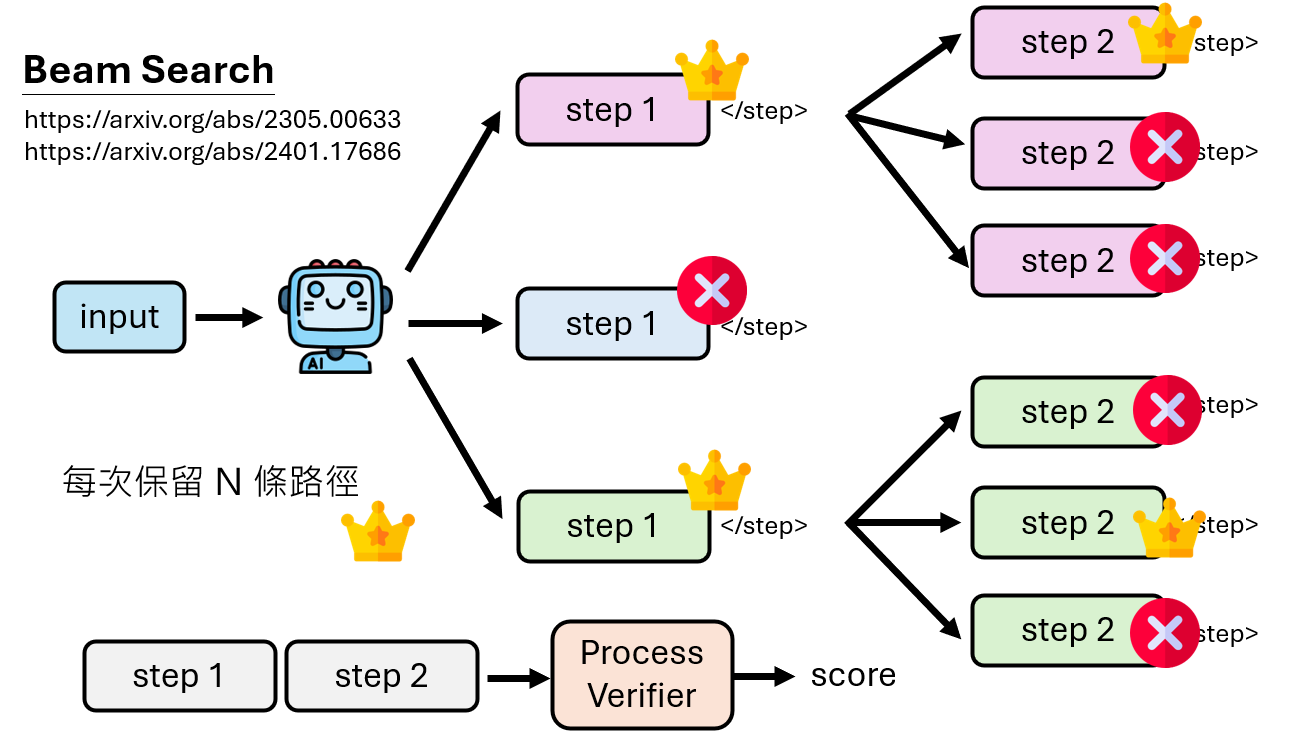
DVTS:Beam Search每次保留的路径有时候会很相似,DVTS可以保留不太一样的路径
更多类似方法(可以直接替换Beam Search):
教模型推理过程(lmitation Learning)
训练数据里面除了答案之外还要有推理过程
推理过程如何获得
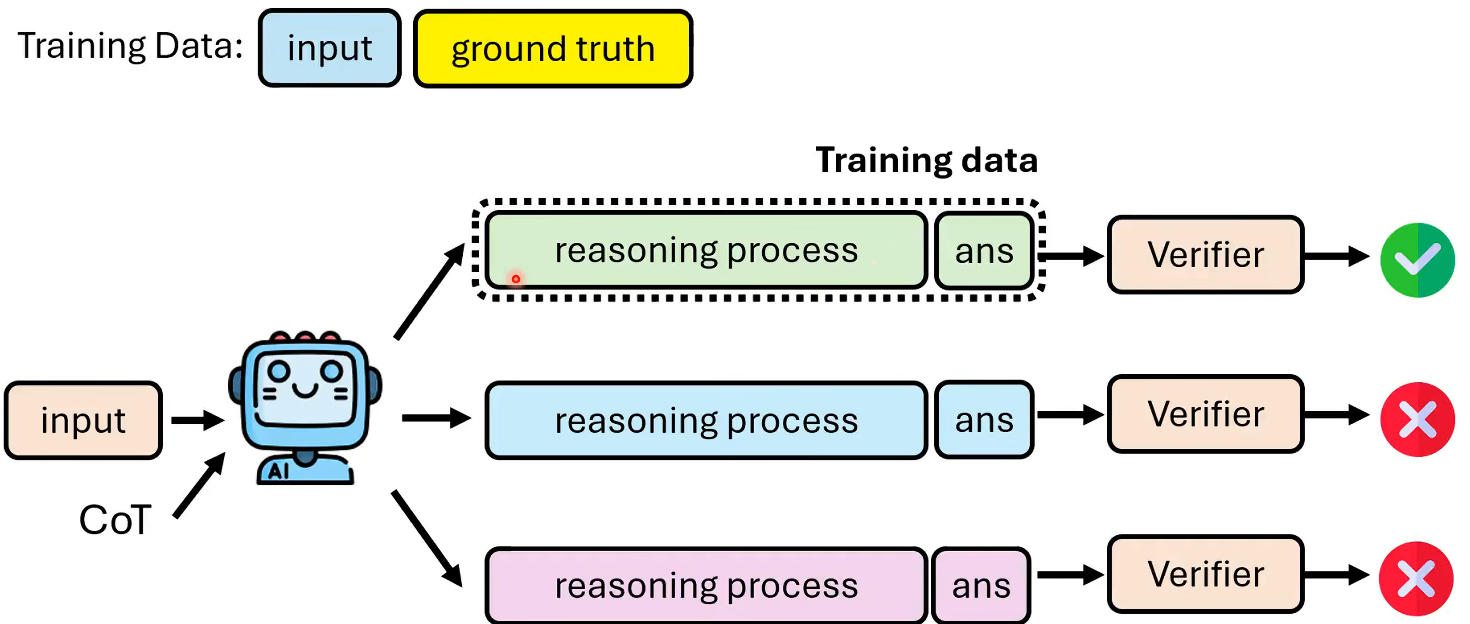
让模型分析多次,选择答案正确的那一条路径;但是有时候有一些问题没有固定的标准答案,可以用一个Verifier来进行判断。
但是,如何保证答案是对的推理过程就是对的呢?
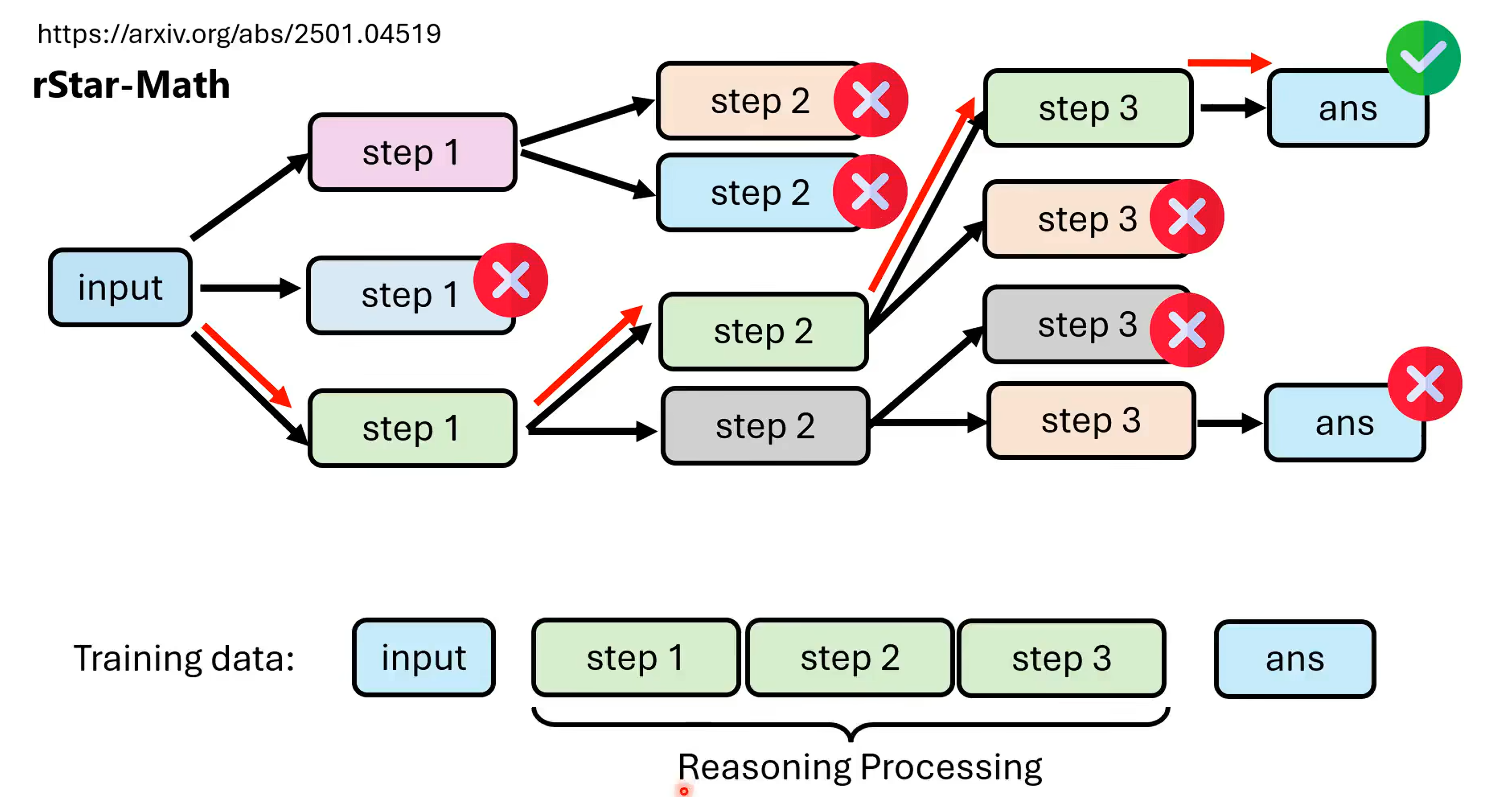
这些数据除了可以应用在SFT上,也可以在RL的过程中使用,如下图,可以使用DPO

推理过程需要每一步都是对的吗?

知错能改善莫大焉。
错误的推理过程后面修改可以告诉模型生成的推理过程可能出错,要自己进行反思;假如推理过程全都是对的,模型会以为自己推理的内容全是正确的,不知道自己找问题。
===>让语言模型有知错能改的能力
如下图所示,模型思考探索以一种深搜的方式,同时把搜到的错误答案也加入到训练中(但是有可能会导致用户看起来像是突然非常突兀的到另外一个答案上,一次可以把Verifier的答案加入进去)。这样整个数据也能让模型学到纠错的能力。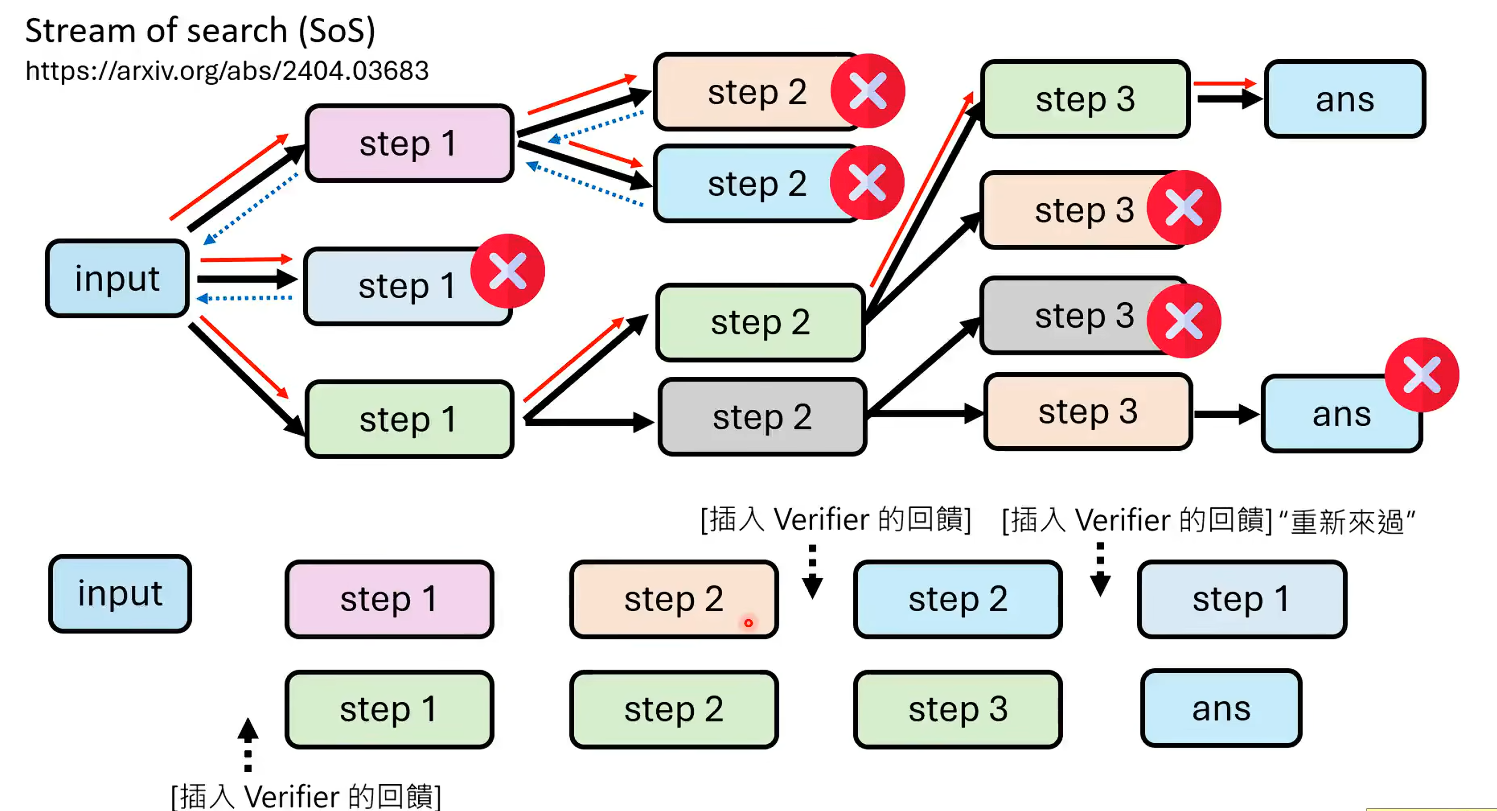
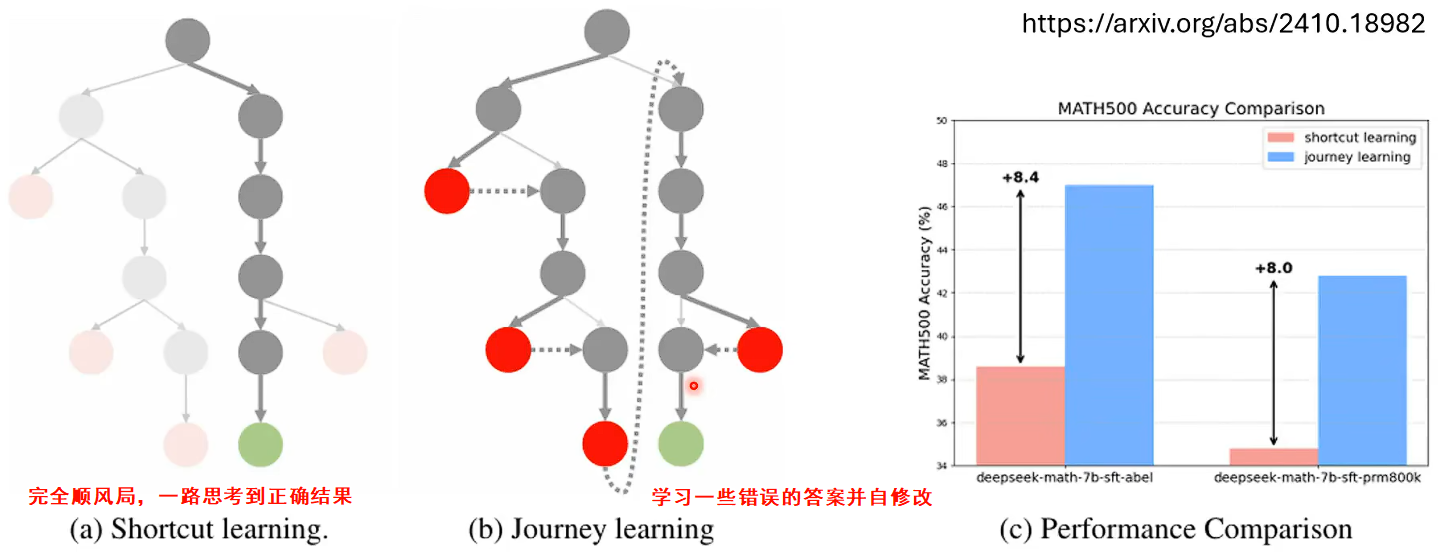
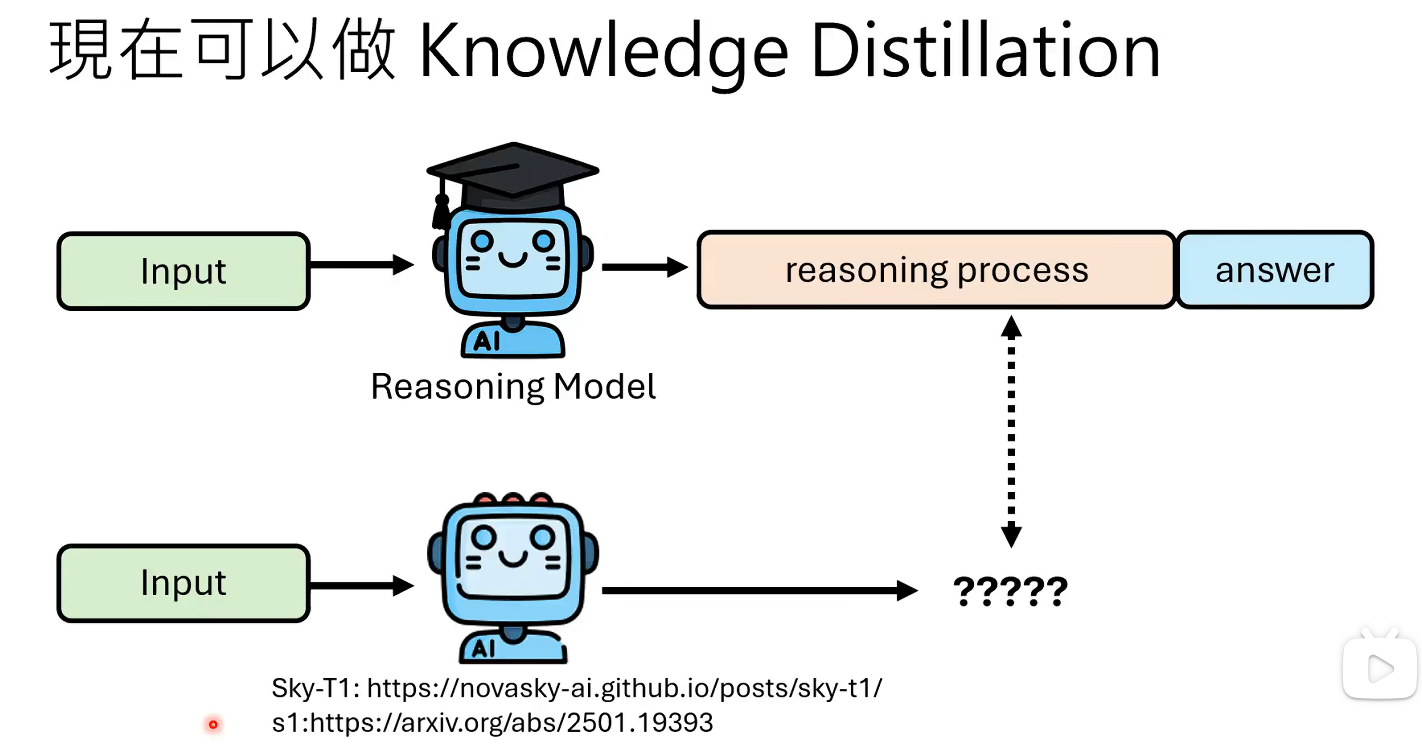
目前有很多有reasoning的模型可以直接蒸馏
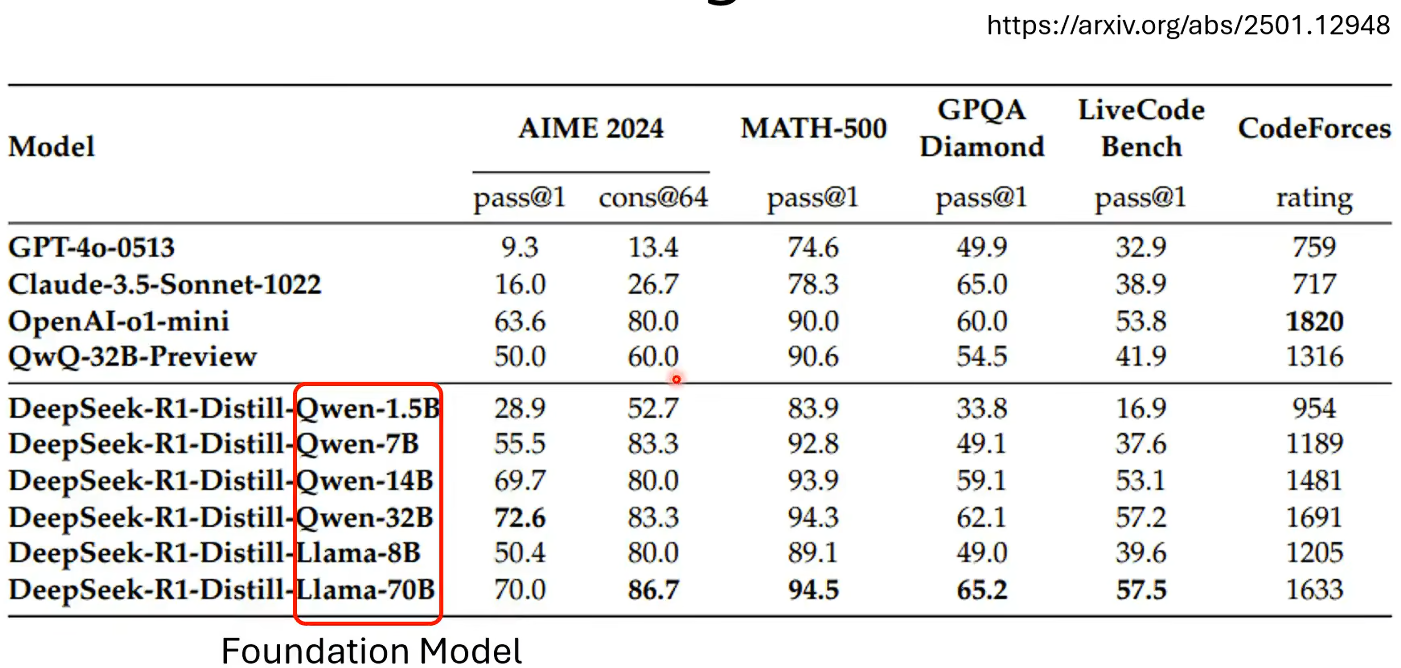
下面是用deepseek-R1当老师蒸馏一些模型,结果都不错
以结果为导向学习推理
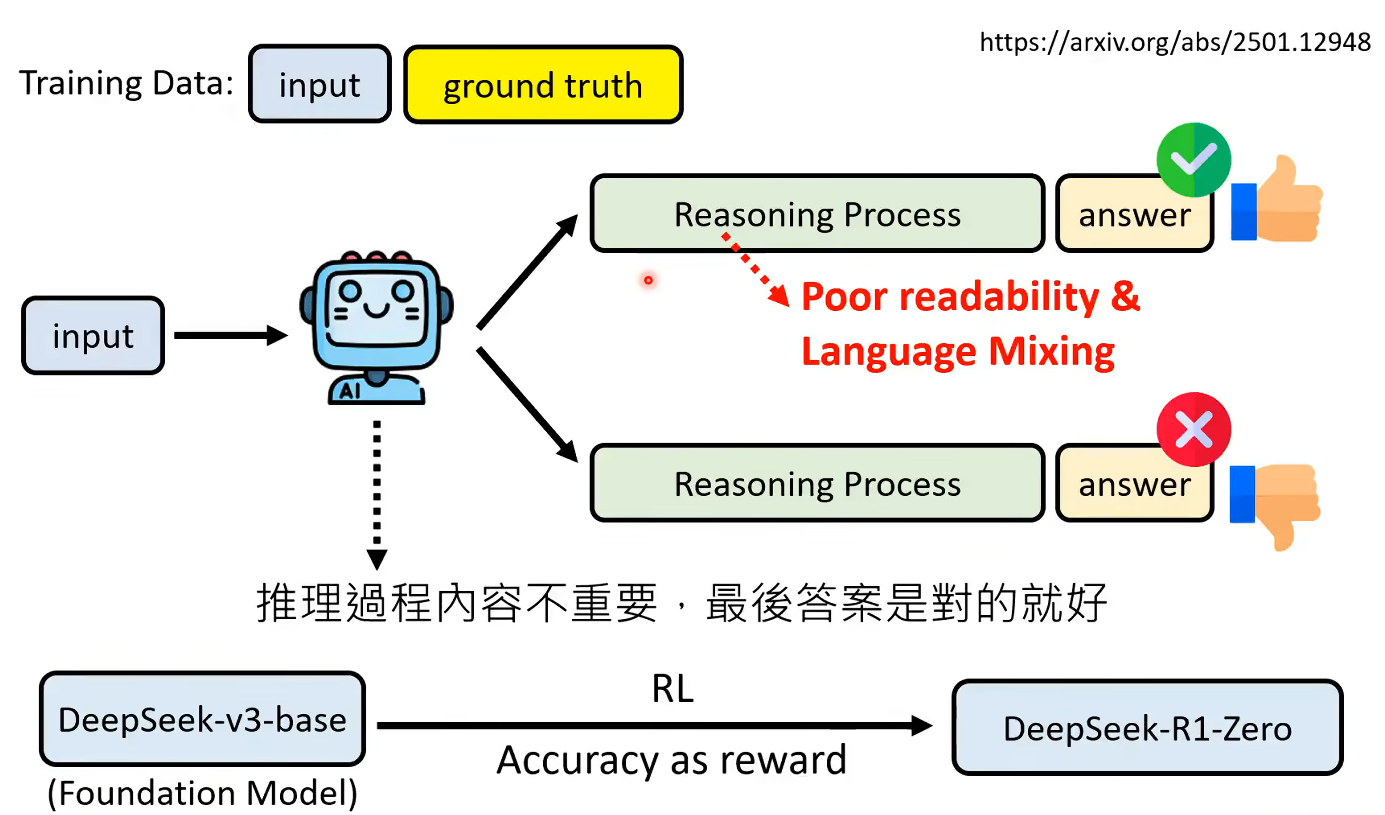
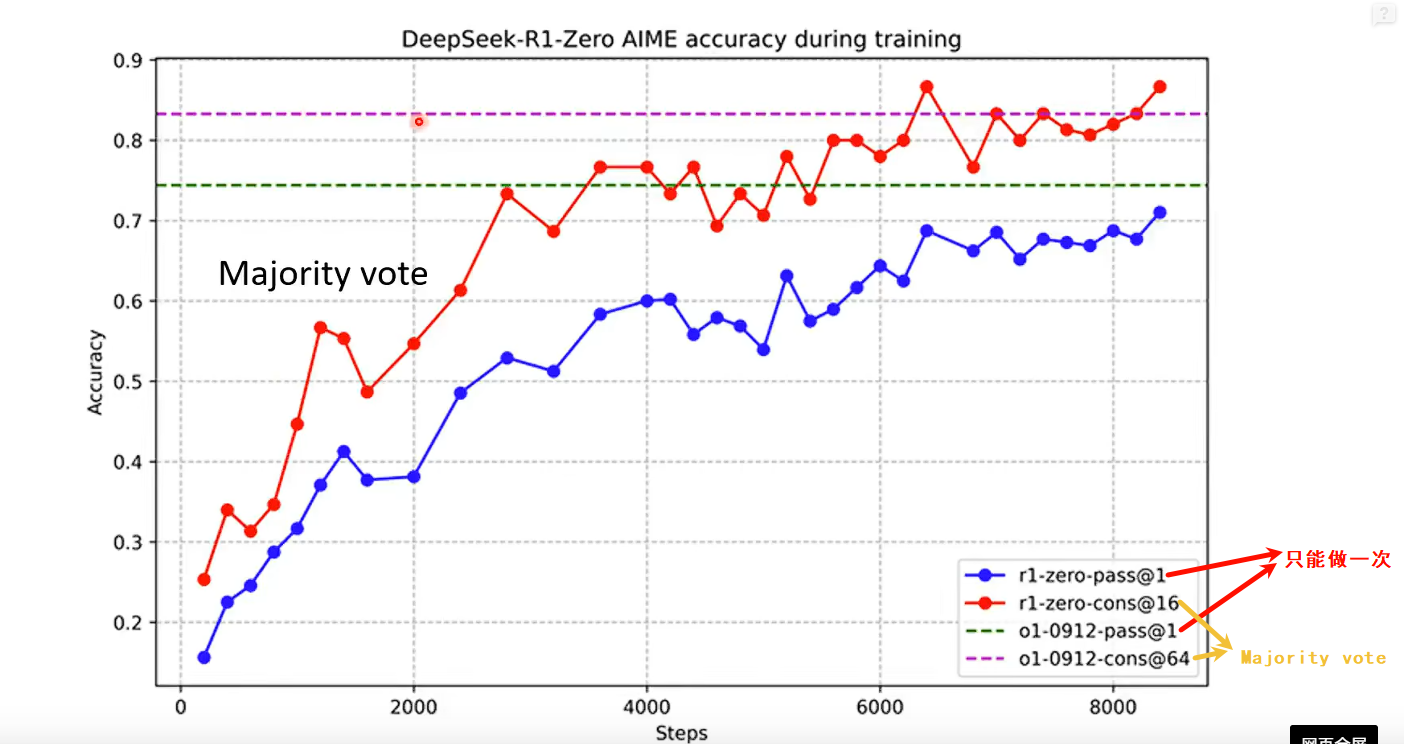
RL过程中,即使不人为教模型找推理中错误,模型自己也可以自动学会

但是deepseek-r1-zero却没有办法拿来使用,因为以结果为导向学习,而不管中间推理过程,导致中间的推理过程乱七八糟人类没有办法看懂,会有各种各样语言等等
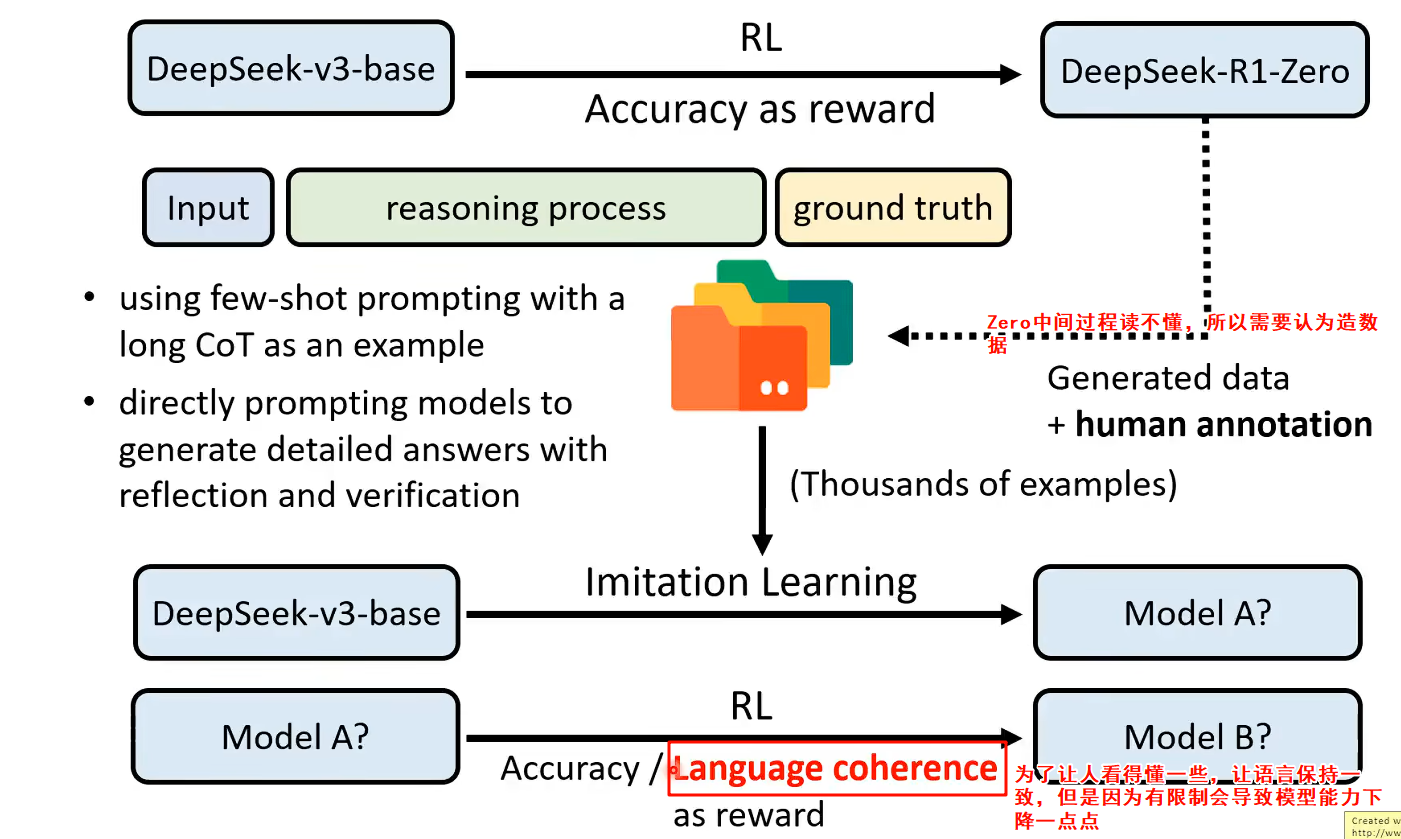
会发现在构造新的数据的过程中,不仅仅只用了RL,还用了本文前面讲的三个方法(cot、Marity Vote等等)
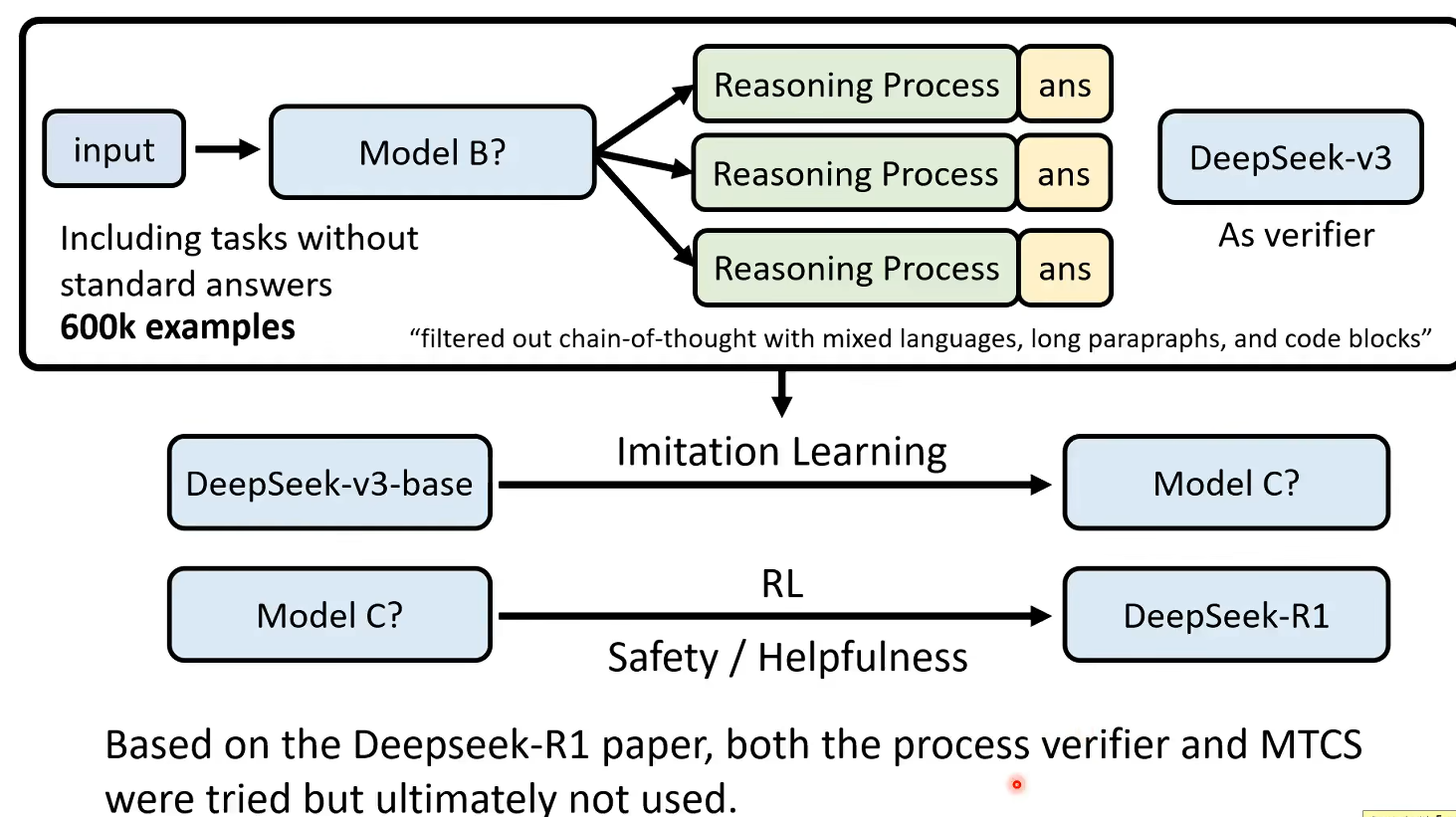
总的来看,DeepSeek的思考过程大多数都是模型自己生成然后训练的,因此DeepSeek的推理过程有时候也会有一些人类看不懂的地方
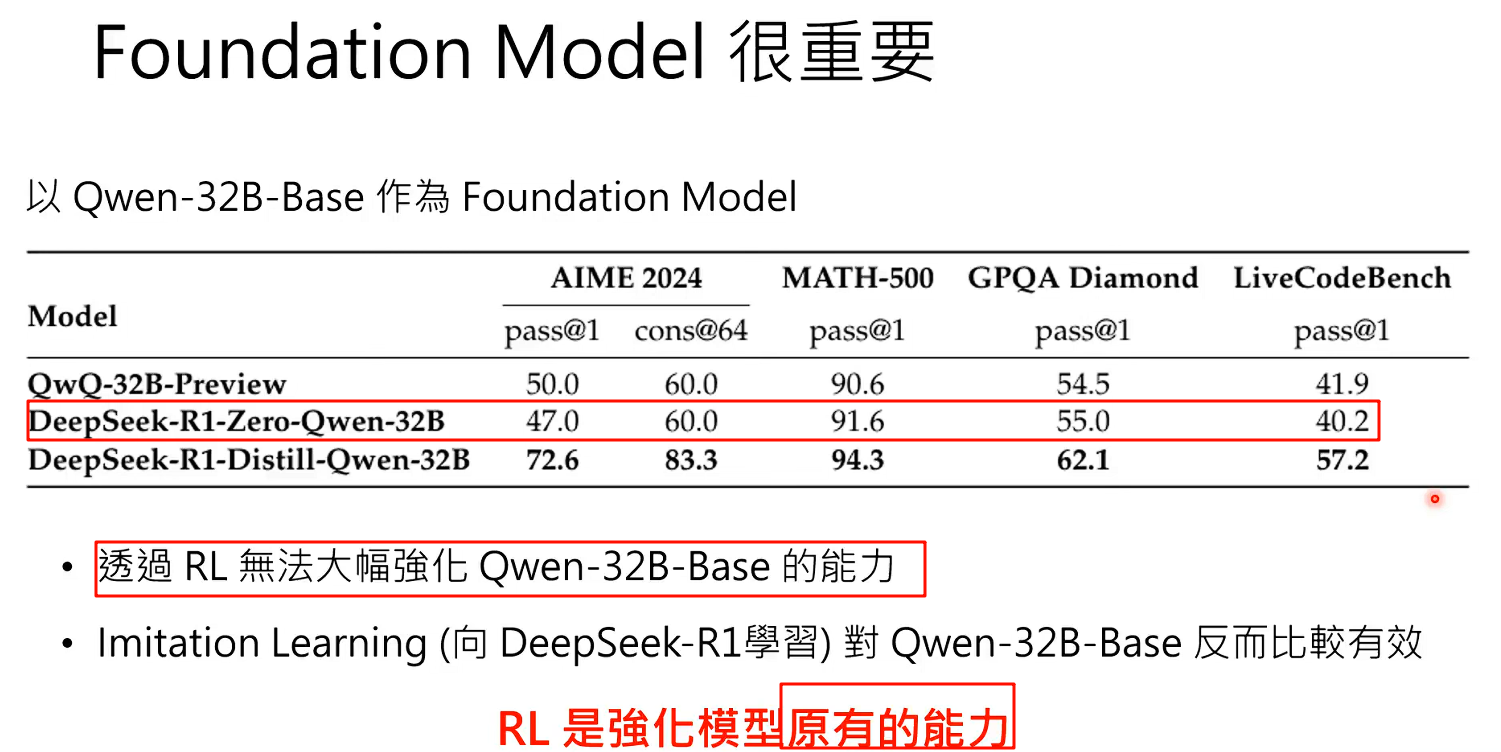
RL是的原理是增加正确答案的几率,但是前提是能产生正确答案,因此模型如果本身能力就不够强,那么RL也无法激发;只有模型本身有某种能力,RL可以激发他的这种能力
所以之前RL后模型有AhaMement是模型本身就有的能力
如何不让模型想太多
有时候模型越长,正确率不一样越高,并且模型输出太长,会很消耗资源
如何避免模型想太多,结合前面4个方法
COT
限制每次思考可以生成的token数

给模型推理流程
人为设计推理流程,因此人为减少一些推理流程
Imitation Learning
让可以推理的模型生成多次答案,选取Reasoning最短的输出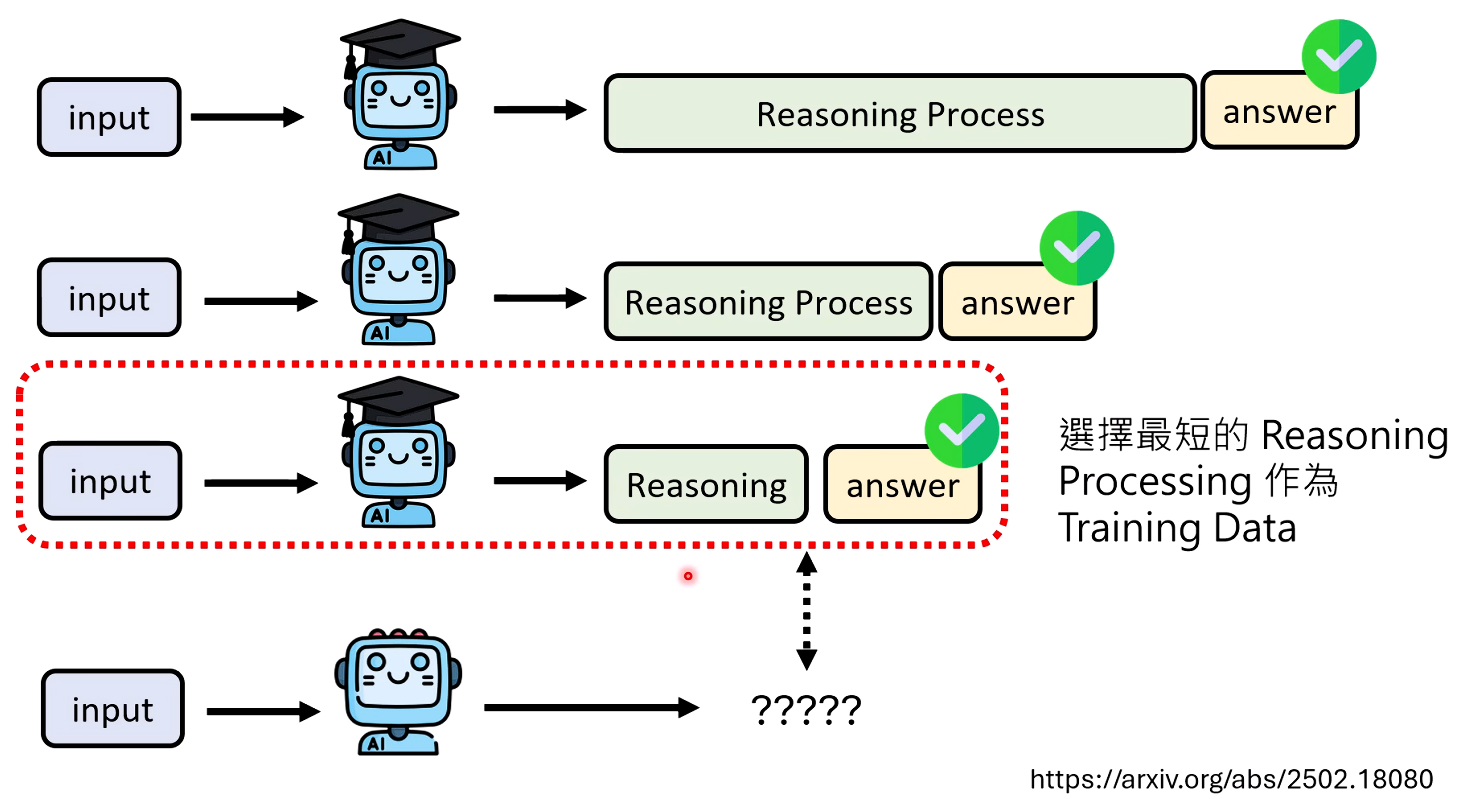
训练逐渐把reasoning的过程慢慢拿掉,让模型学会“心算”,也能达到较好的效果(在比较简单的问题上,如下面的乘法)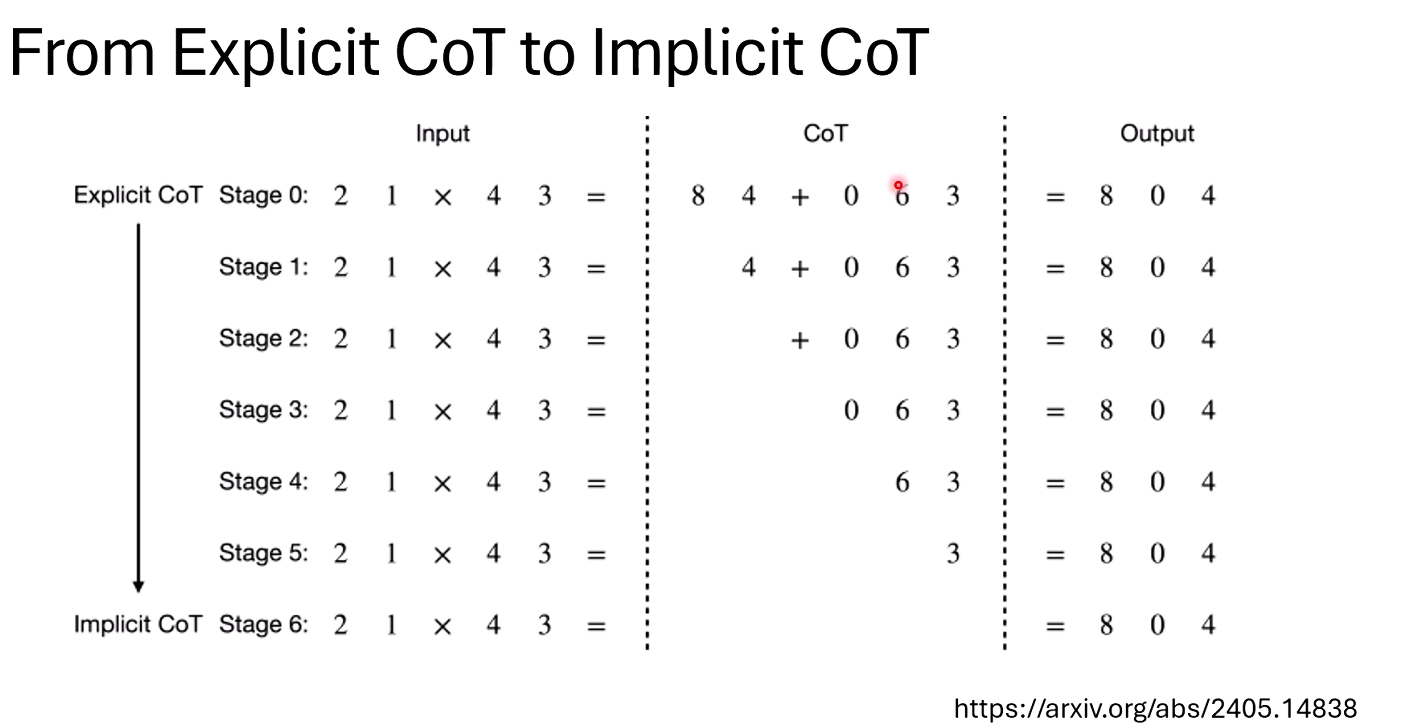
Reinforcement Learning
在R1-zero不断RL的过程中,随着step不断增多,reasoning 的长度也越来越长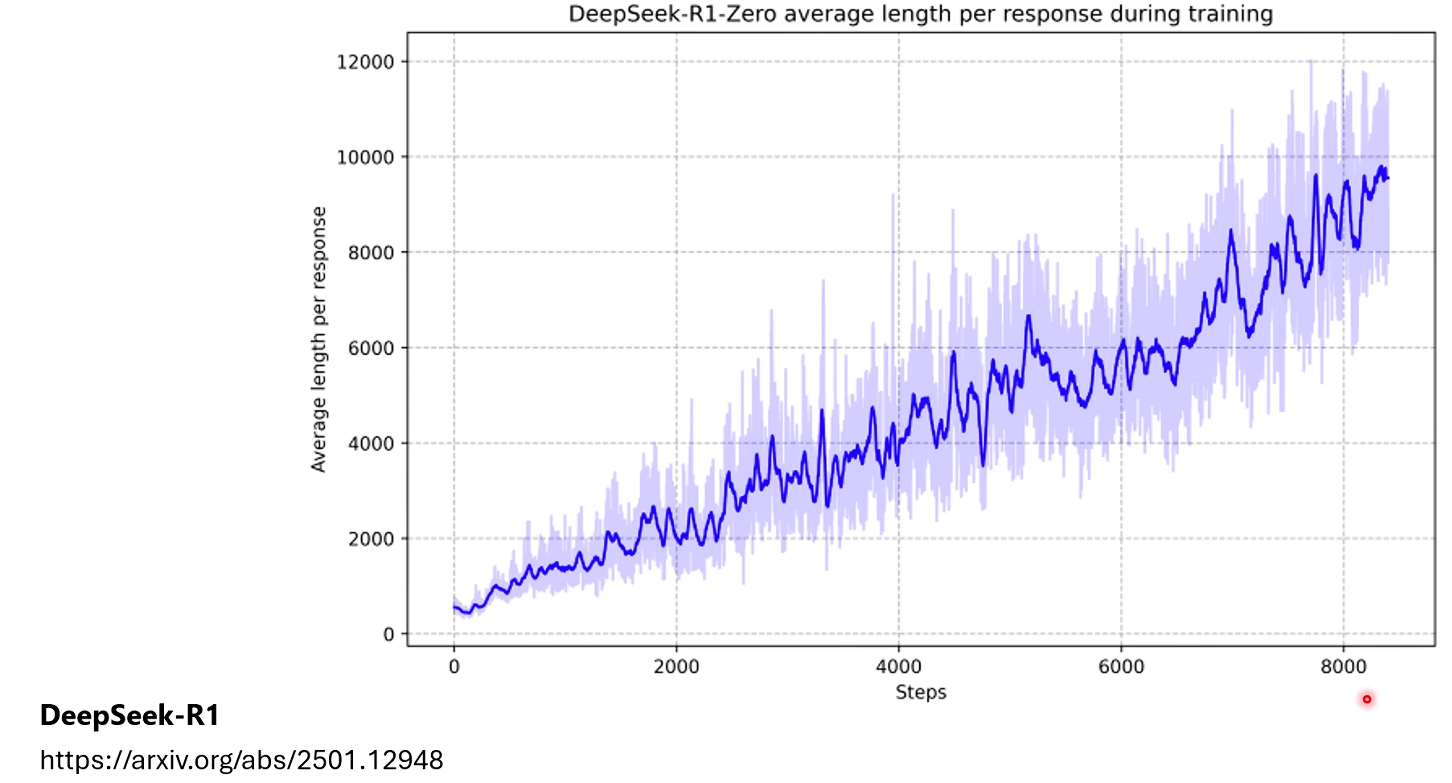
但是其实在模型RL的过程总,并没有教模型说生成的长度越长越好。
那么如何控制模型reasoning的长度呢?直接一刀切说reasoning的长度要在多少以下?显然是不行的,不同的问题设定的肯定不一样,较难的问题可能需要较长的reasoning,较简单的问题可能只需要很短的reasoning
把长度也加入到reward的当中去。让模型生成多个答案,取平均长度,若生成的长度小于平均长度,则鼓励。
也可以在输入中控制推理的长度
继深度思考模型展示出强大的推理(Reasoning)能力后,一个新的问题浮出水面:这些模型似乎“想得太多”了。本文基于李宏毅教授的最新课程,深入探讨了如何解决大型语言模型(LLM)推理过程冗长、效率低下的问题。文章首先通过严谨的实验数据,打破了“推理越长,结果越好”的普遍迷思,并确立了“在有限资源下追求最佳表现”的核心工程准则。随后,文章沿着上期课程提出的四大技术流派,系统性地探讨了控制和优化推理长度的解决方案,包括“草稿链”提示法、学习最短正确路径、内化推理过程,以及将“效率”作为核心指标引入强化学习的激励机制。最后,文章以“长颈鹿的演化”为喻,深刻警示了在AI训练中过度优化单一指标可能带来的负面影响。
1. 推理的悖论:越长越好,还是过犹不及?
上期课程我们探讨了如何让LLM具备深度思考的能力,但这种能力似乎正走向一个极端。许多先进的推理模型,在面对简单问题时,本可一语中的,却偏要“左思右想”,耗费大量计算资源,生成数千甚至上万词的冗长分析。这引出了一个核心问题:更长的推理,真的能带来更好的结果吗?
1.1 打破“长度=质量”的迷思
许多初步研究似乎表明,推理长度与正确率之间存在“负相关”——即推理越长,答错的概率反而越高。然而,这种观察结论可能存在谬误。李宏毅教授指出,这种相关性并不能直接推导出因果关系。一个更合理的解释是,存在一个共同的潜在因素:问题的难度。
- 高难度问题 → 模型需要更长的推理来尝试解决 → 推理过程变长
- 高难度问题 → 模型更容易答错 → 正确率下降
因此,问题的难度同时导致了“推理变长”和“正确率下降”,造成了两者之间虚假的负相关性。
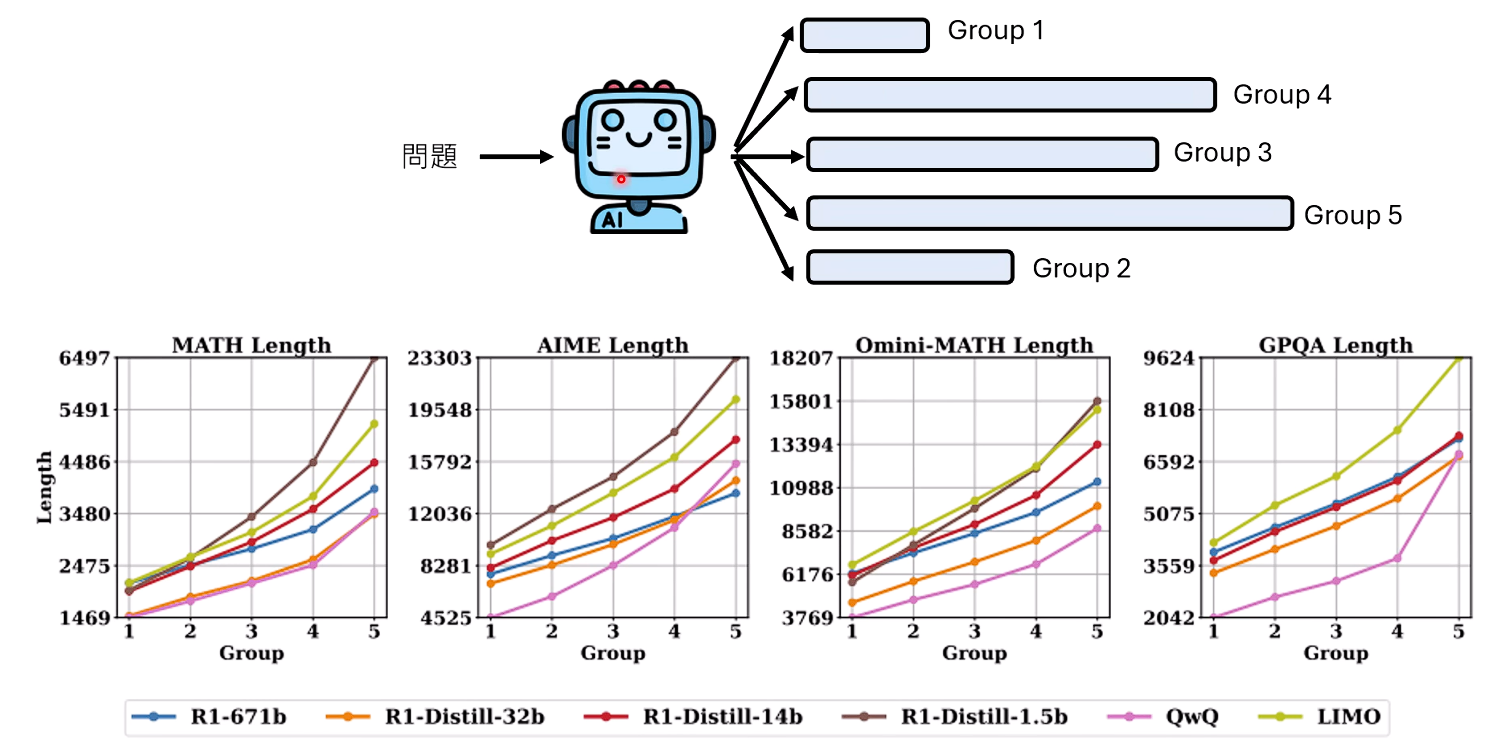
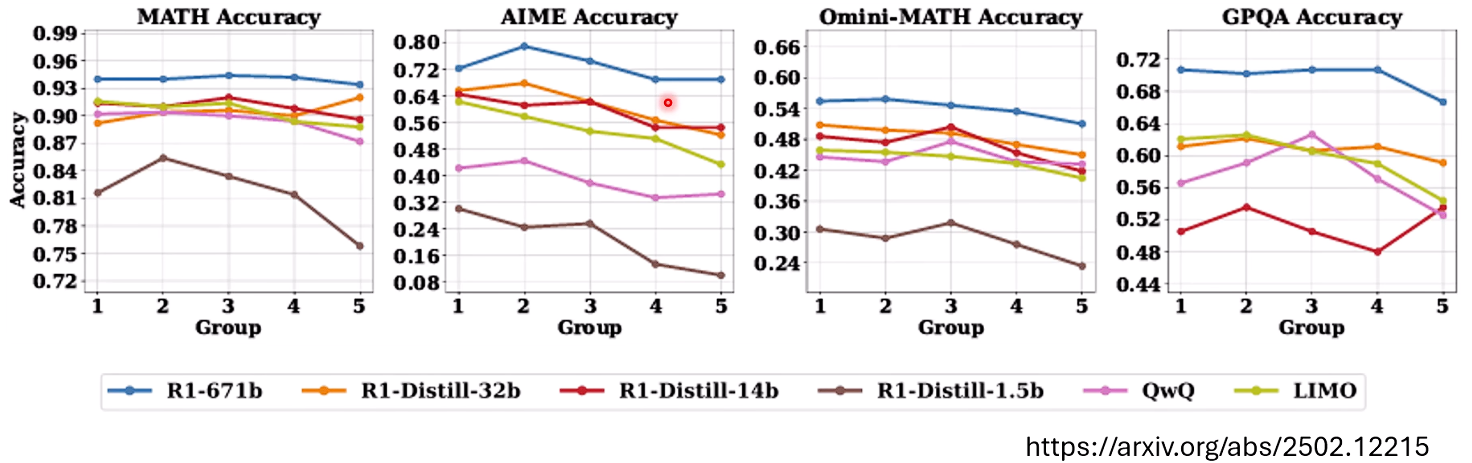
为了得到更严谨的结论,一些研究采用了更精妙的实验设计。例如,让同一个模型对同一个问题回答五次(由于LLM的随机性,每次的推理长度和答案都可能不同),然后根据推理长度将这五次回答分为五个组(Group 1最短,Group 5最长),再分别计算每个组的正确率。
实验结果令人深思:
- 普遍冗长: 即便是“最短”的推理,长度也已相当惊人,动辄达到5000至10000个Token。
- 长度与正确率无明确正相关: 在AIME(美国数学邀请赛)等多个测试集上,从Group 1到Group 5,随着推理长度的增加,正确率并无持续提升的趋势,甚至在某些情况下还会下降。
这些实验有力地证明:对于同一个问题,一味地增加推理长度,并不能保证带来更好的结果。
1.2 最优工程师准则:有限资源下的最佳表现
这一发现引导我们回归到一个根本的工程哲学:最好的工程师,不是在无限资源下将事情做到完美,而是在有限资源下将事情做到最好。
这个准则同样适用于人工智能。一个保证100%正确但每个问题都需要推理一年的AI,对我们毫无价值。我们真正期待的,是一个能够在有限的算力、时间和成本内,最大化其表现的智能系统。因此,如何避免模型“想太多”,让推理变得“高效”,成为了当前LLM领域的一个关键课题。
2. 如何让AI“恰到好处”地思考?四大路径探索
针对上期课程中提到的四种赋予模型推理能力的技术流派,我们可以相应地探索优化其推理效率的方法。
2.1 路径一:从提示入手——“草稿链”的简洁之道
这是最简单直接的优化方法,在不改变任何模型参数的情况下,通过修改提示(Prompt)来约束模型的行为。
问题: 基础的“链式思考”(Chain-of-Thought)提示,如“Think step by step”,往往会诱导模型进行不受约束的长篇大论。
解决方案:“草稿链”(Chain of Draft)。这是一种改良的提示策略,它在要求模型分步思考的同时,增加了简洁性的约束。例如:
“Think step by step, but each thinking step is just a draft, and each line of the draft should not exceed five words.”
效果: 实验证明,这个看似微小的改动效果显著。在Claude 3.5等模型上,“草稿链”大幅缩短了输出长度,同时并未对正确率造成明显损害,有时甚至略有提升。
2.2 路径二:优化工作流——人为掌控推理尺度
当使用外部工作流(如蒙特卡洛树搜索、束搜索)来引导模型推理时,控制推理的“尺度”是完全由人类设计者掌控的。我们可以通过调整工作流的参数来平衡效率和性能:
- 减少采样数量: 在需要模型生成多个候选答案时,减少生成的数量。
- 缩小搜索空间: 在使用束搜索(Beam Search)时,减小束的宽度(beam size);在使用树搜索时,限制树的深度和广度。
由于控制权完全在设计者手中,这是一种直接且可预测的效率优化方式。
2.3 路径三:模仿学习的“瘦身”——学习最短路径与内化推理
模仿学习的核心是让“学生模型”学习“教师模型”的推理过程。我们可以通过优化其学习内容,来培养一个更高效的学生。
- 方法一:学习最短的正确路径。
- 让强大的教师模型对同一个问题进行多次推理。
- 收集所有最终答对的推理路径。
- 从这些正确的路径中,挑选出长度最短的那一条,作为学生模型的训练样本。
- 通过这种方式,学生模型学会了用最简洁有效的方式解决问题。
- 方法二:从显式推理到隐式推理(Explicit to Implicit CoT)。
- 这是一种旨在让模型“内化”思考过程的渐进式训练方法。
- 第一步: 正常训练模型,让其学习完整的、显式的推理过程。
- 第二步: 在训练数据中,逐步、逐个地删掉推理过程开头的Token。
- 第三步: 持续这个过程,直到训练数据中的推理过程被完全删除。
- 目标: 最终训练出一个能够直接从问题跳到答案的模型,它已经将推理过程“学会了”,但不再需要将其显式地写出来,而是像人类一样在“心里”完成计算。研究表明,在一些相对简单的数学任务上,这种方法可以实现性能无损的“心算”。
2.4 路径四:重塑激励机制——将“效率”写入强化学习
标准的强化学习(RL)在训练推理模型时,通常只奖励“正确答案”,而对推理过程的长度不作任何惩罚。这导致模型有动机进行无限长的推理,只要能提高最终答对的概率。DeepSeek-Coder-V2的训练过程就观察到,随着RL的进行,模型的输出长度会自发地越来越长。
要解决这个问题,必须将“效率”也加入到奖励(Reward)函数中。
- 错误尝试:设定固定的长度门槛。 例如,规定推理超过1000个Token就扣分。这种“一刀切”的方法并不合理,因为它忽略了不同问题的难度差异。
- 更优方案:使用相对标准。
- 针对一个问题,先让模型多次推理,统计出所有正确解答的平均推理长度。
- 在RL训练中,新的奖励机制变为:
- 高额正奖励: 答对 且 推理长度短于平均值。
- 低额正奖励/无奖励: 答对 但 推理长度长于平均值。
- 负奖励: 答错。
- 这样,模型就被激励去寻找更简洁的正确解法。
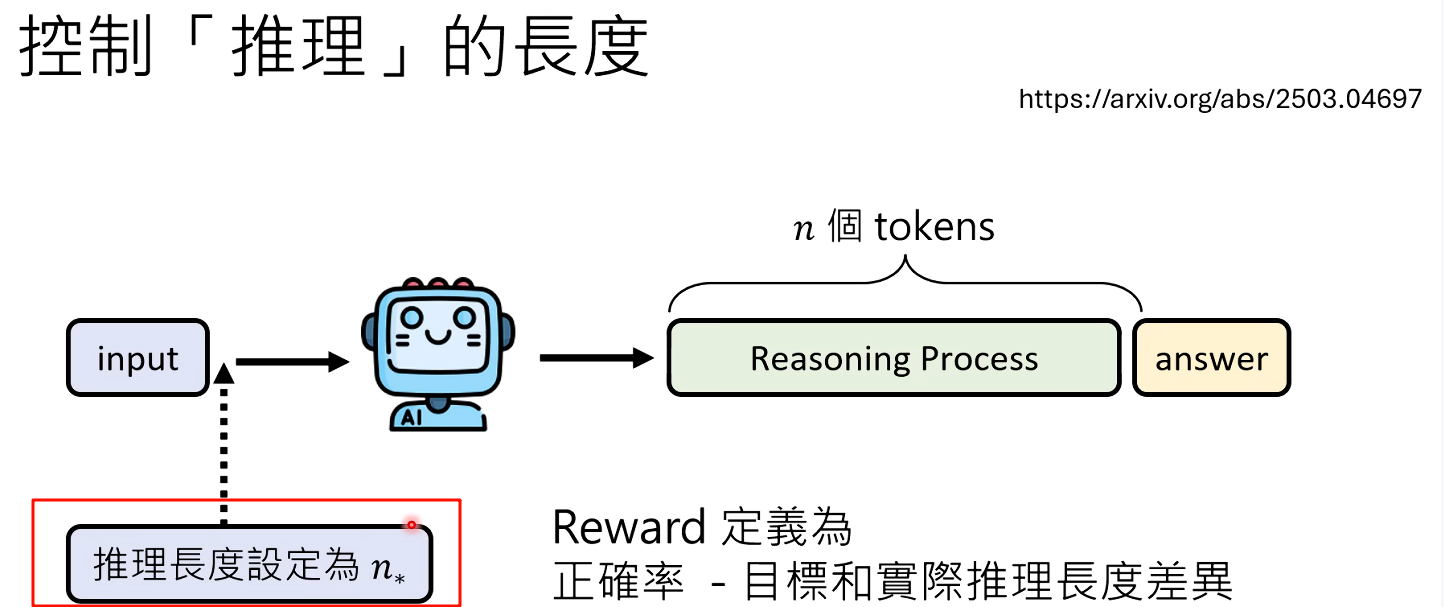
- 终极方案:训练可控的推理长度。
- 在输入中加入一个指令,告诉模型本次推理的目标长度(例如,“推理长度必须设定为N个字”)。
- 奖励函数变为:
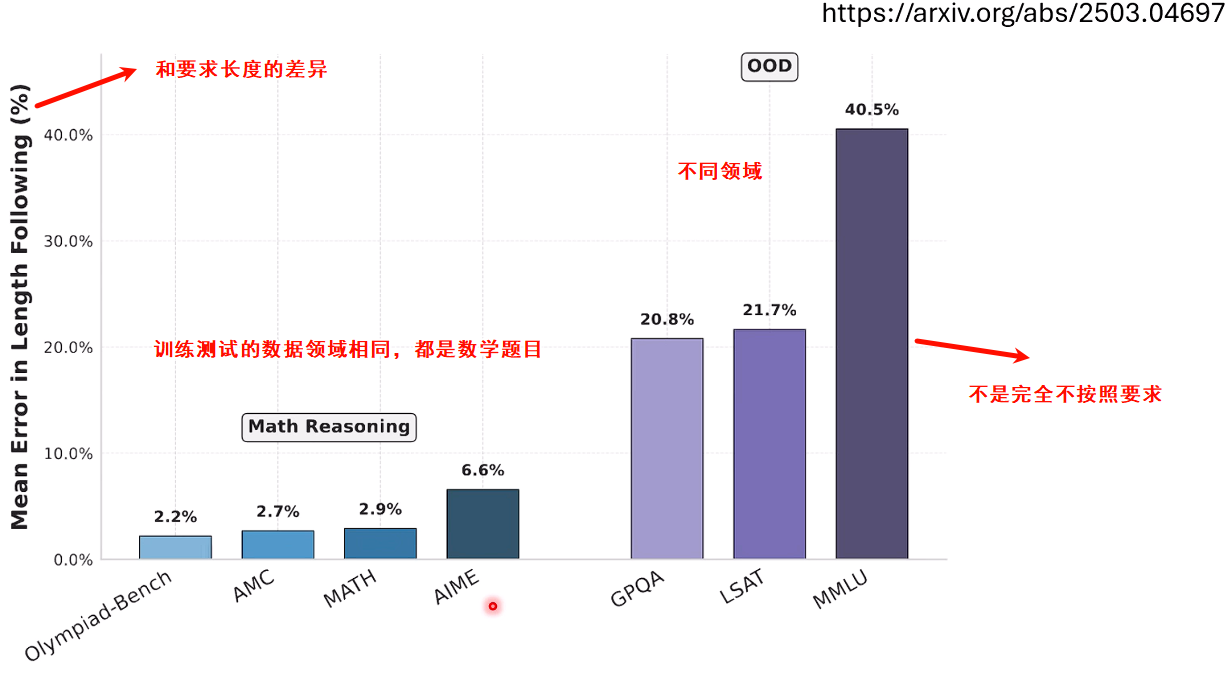
正确率 - |实际长度 - 目标长度|。 - 实验表明,通过这种方式,模型不仅能学会控制其输出长度,而且在被要求进行长推理时,其性能与未受控的模型相当;在被要求进行短推理时,其性能也优于被粗暴截断的模型。这赋予了使用者根据可用算力动态调整模型推理深度的能力。
3. 总结与启示:警惕“长颈鹿的脖子”
当前LLM推理的冗长趋势,与一个经典的生物学故事惊人地相似:长颈鹿的演化。
生物课本告诉我们,长颈鹿演化出长脖子是为了吃到高处的树叶,这是一种生存优势。然而,演化学家发现,长颈鹿的脖子“长得太长了”,甚至超过了大多数树的高度,导致它们进食时反而需要费力地低下头。
为什么会发生这种“过度优化”?一种解释是“性选择”的介入。当“长脖子”成为一种优势符号后,它就成了吸引异性的标准。于是,演化的驱动力从“实用”转向了“攀比”,脖子越长越能获得繁殖机会,其实际功能反倒被忽略。最终,过长的脖子成了消耗巨大能量的负担,在环境恶劣时反而成为生存的劣势。
LLM的推理长度正在上演同样的故事。一定长度的推理是必要的“生存优势”。但当训练的激励机制(如单纯的RL)只奖励“正确”这一个指标时,就如同演化中的“性选择”,模型会不计成本地增加推理长度来“炫技”,以期获得更高的奖励分数。这是一种过犹不及。
这堂课的核心启示在于,我们设计和训练AI时,必须警惕这种“长颈鹿的脖子”现象。一个真正高效、智能的AI,不应是无休止思考的“思想巨人”,而应是懂得在恰当的时候、用恰当的资源、做恰当的思考的“智慧工程师”。未来的研究,必将围绕如何实现这种智能与效率的完美平衡而展开。