语言模型内部运行机制
在之前的课程中探讨了如何利用大模型构建AI Agent。课程不讨论模型的训练过程,而是假设我们拥有一个已经训练好的、功能完备的LLM。我们的目标是:理解这个庞大而复杂的神经网络,在面对输入并生成输出的每一个瞬间,其内部究竟发生了什么。
重要提醒: 正如李宏毅老师在课程开始时强调的,目前绝大多数的这类分析研究,受限于计算资源,往往是在相对较小或较早期的开源模型(如GPT-2、LLaMA系列早期版本)上进行的。这就像是通过研究老鼠的大脑来推断人类大脑的运作机制。虽然基本原理可能相通,但我们必须认识到,这些结论不一定完全适用于最新、最顶尖的闭源模型。然而,这些开创性的研究为我们提供了一套宝贵的分析方法论和深刻的洞见。
本次探索将分为四个部分:
- 单个神经元在做什么?——从最基础的单元开始。
- 一层神经元在做什么?——从个体到群体的协作模式。
- 跨层神经元如何互动?——追踪信息在网络中的完整流动路径。
- 让模型亲口说出自己内心的想法——利用LLM的语言能力进行自我剖析。
单个神经元在做什么?
如何探究一个神经元的功能呢?通常遵循一个三步流程:
是否具有相关性:当该神经元“启动”时(可以理解为RELU函数大于0的部分被激活),模型会说脏话,这说明该神经元与“说脏话”这一行为相关。
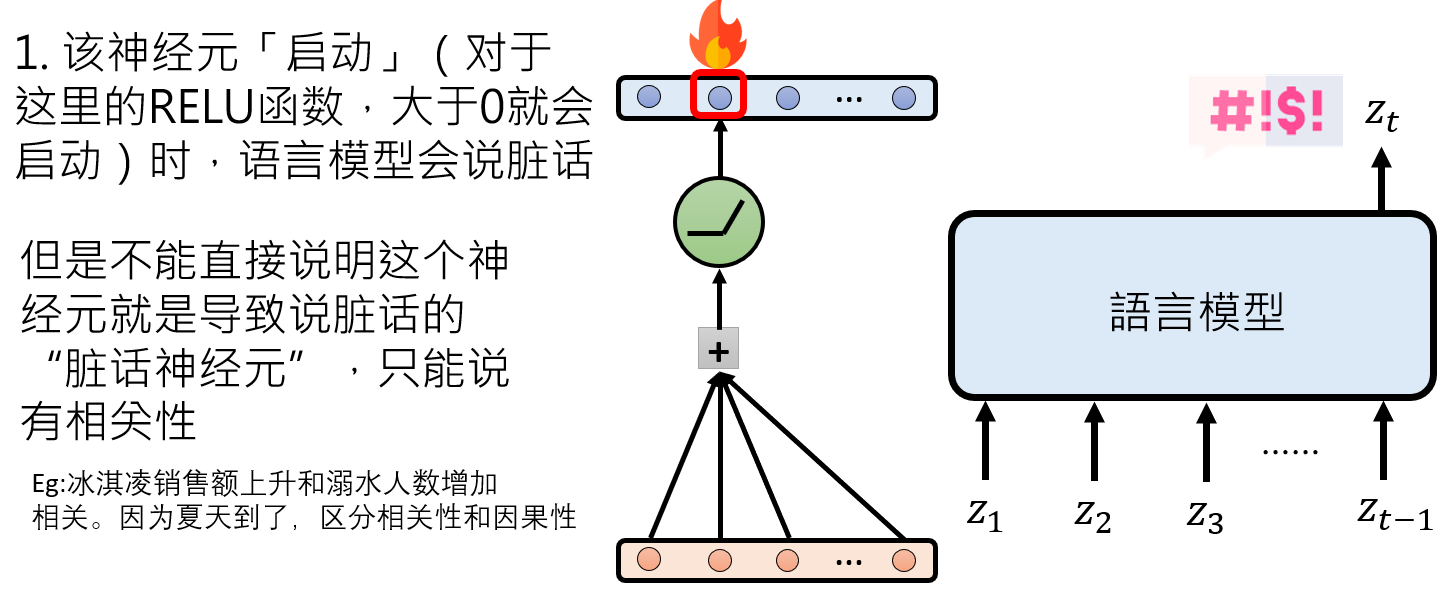
移除该神经元(因果性):最直接的方法是“敲除”(Ablation)这个神经元,即强制将其输出设为零(但是事实上设置为0依旧有影响,可能在大量数据上的取平均激活值会效果较好(尚待研究))。如果敲除后,模型在各种挑衅下都无法生成脏话,我们就能更确信这个神经元对“说脏话”有因果作用。
控制启动程度(option):如果可能,尝试不同程度地激活该神经元,观察其输出的变化。比如,轻微激活时说轻度脏话,强烈激活时则言辞激烈。但是如何表明最终说脏话的程度呢?所以一般实验不做这一步
单一神经元的功能并不容易被解释
历史上最著名的例子莫过于2021年在OpenAI的CLIP(一个图像-文本多模态模型)中发现的**“川普神经元”**。研究人员发现,某个特定的神经元对于与唐纳德·川普相关的各种输入都表现出极高的激活度,包括他的照片、漫画形象,甚至是在图像中出现的“Trump”文字。这种选择性非常高,对于奥巴马等其他政治人物则几乎没有反应。
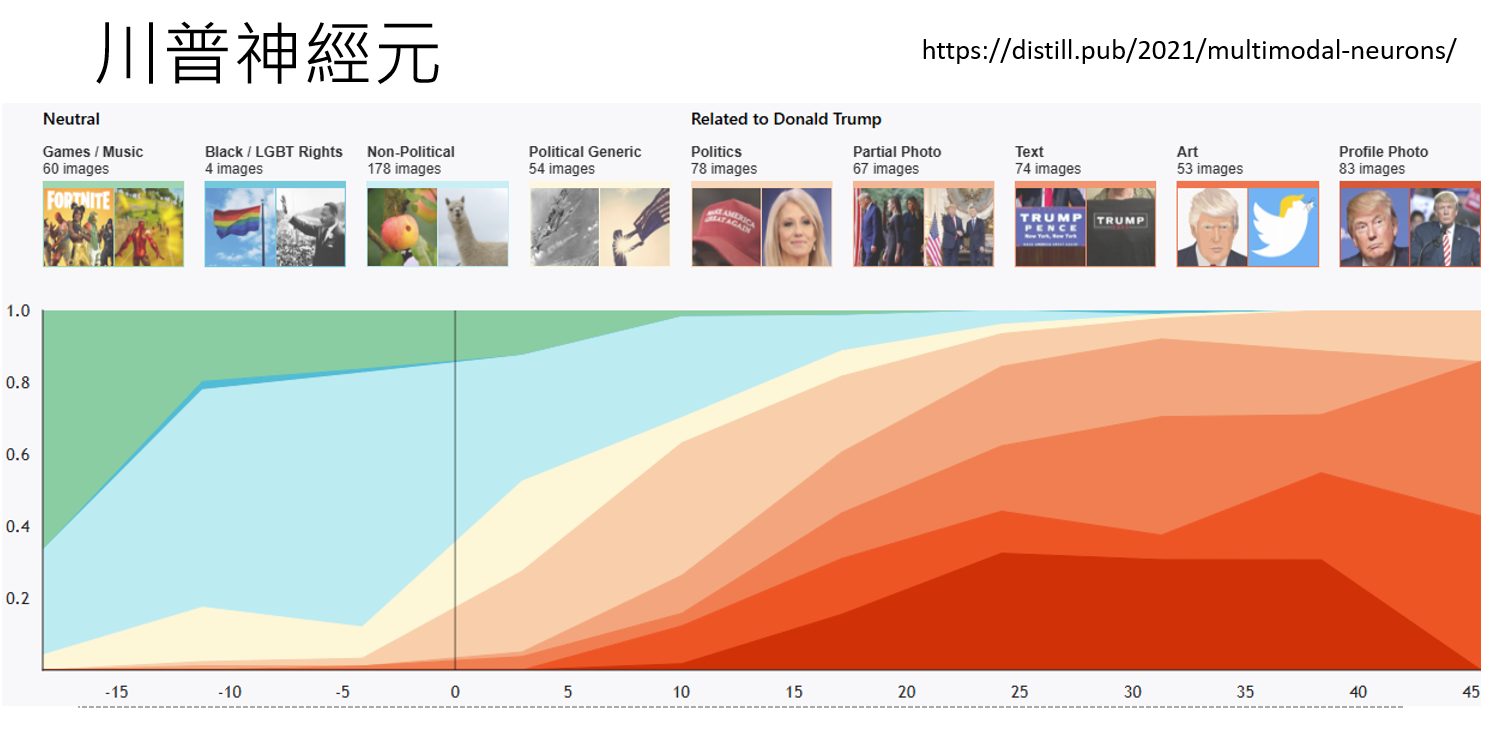
然而,“川普神经元”这样的“祖母神经元”(Grandmother Neuron,一个脑科学中的假说,指专门负责识别特定概念如“你祖母”的单个神经元)在LLM中其实是凤毛麟角。现实更为复杂:
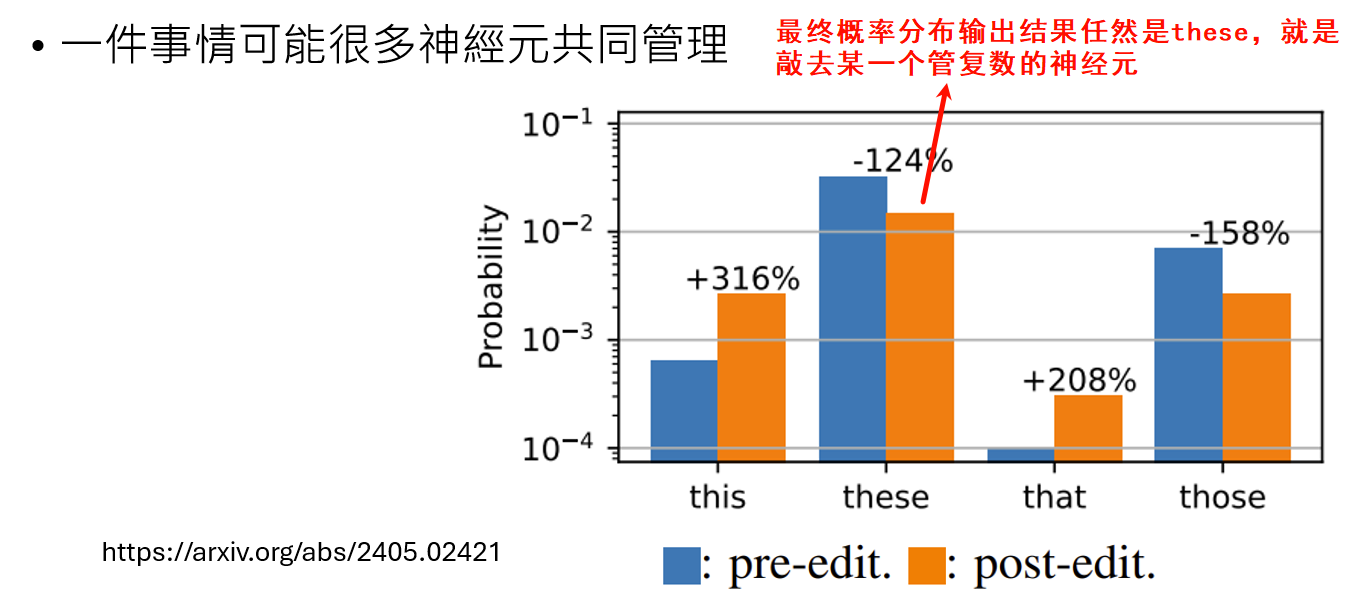
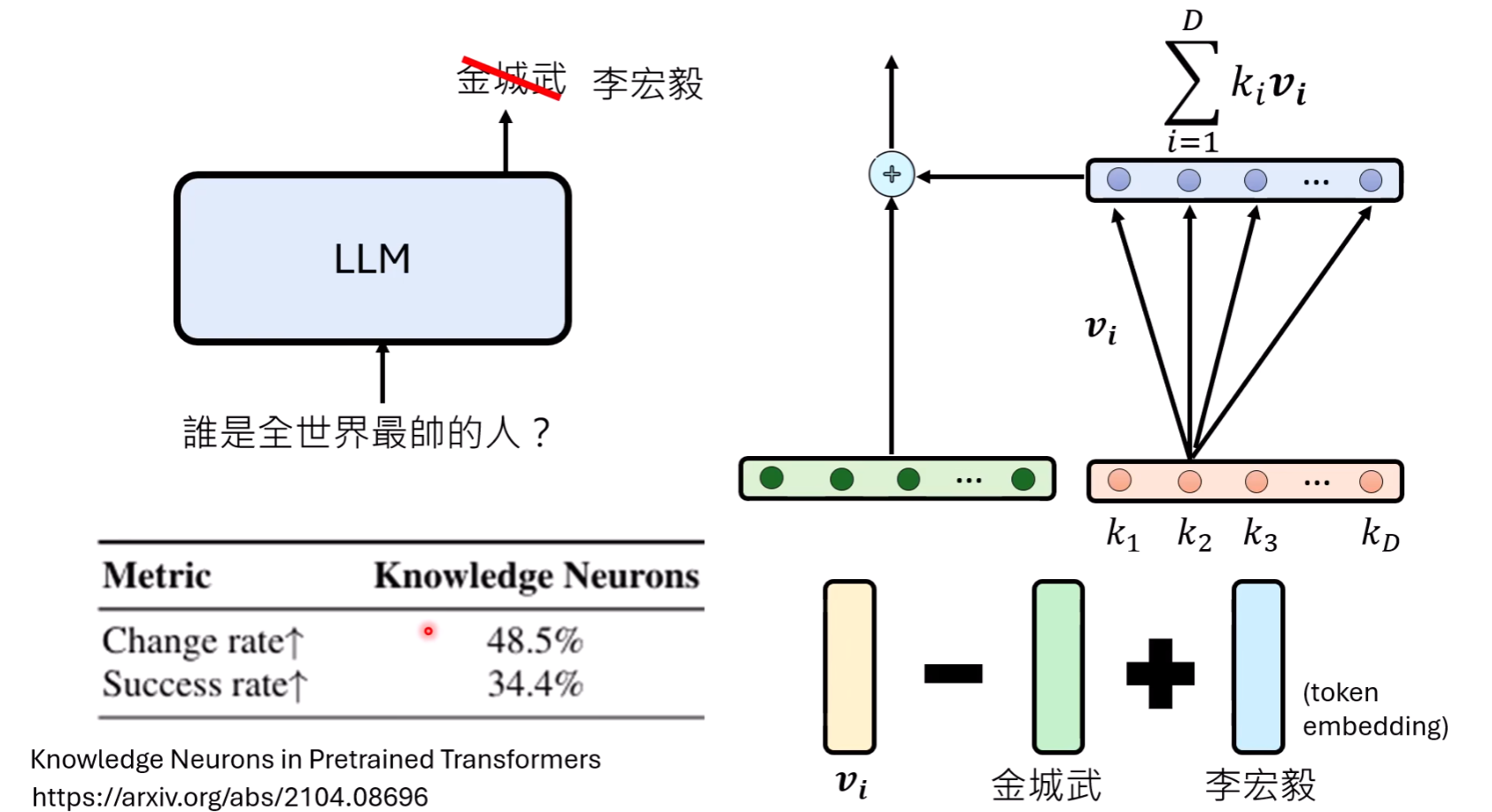
一件事情可能由多个神经元共同管理:一个宏观概念(如“复数”)通常由多个神经元共同控制。一篇研究发现,即便找到了控制单数和复数的特定神经元,单独敲除其中一个,虽然会显著改变相关词汇的输出概率,但由于其他神经元的“补偿”作用,最终模型输出的词语(概率最高的那个)往往保持不变。这意味着系统具有鲁棒性,单个神经元的失效不足以改变宏观行为。
一个神经元可能同时管很多件事:反过来,一个神经元也可能参与到多个看似无关的概念中。当我们观察一个随机神经元的激活文本时,常常会发现其模式杂乱无章,难以用一个简洁的人类概念来概括。GPT-4.5在解释一个这样的神经元时,给出的结论是它“似乎与物理学、医学术语、伪造相关的词汇以及特定人名有关”——这几乎等于没有解释。

这背后的根本原因在于模型的“效率”。一个LLM的FFN层可能只有几千个神经元(例如4096个),却要编码整个世界海量的知识和概念。如果严格遵守“一个神经元一个概念”的原则,模型的表达能力将极其有限。因此,更合理的假设是,模型用神经元的组合,即高维空间中的一个方向(向量),来编码一个功能或概念。
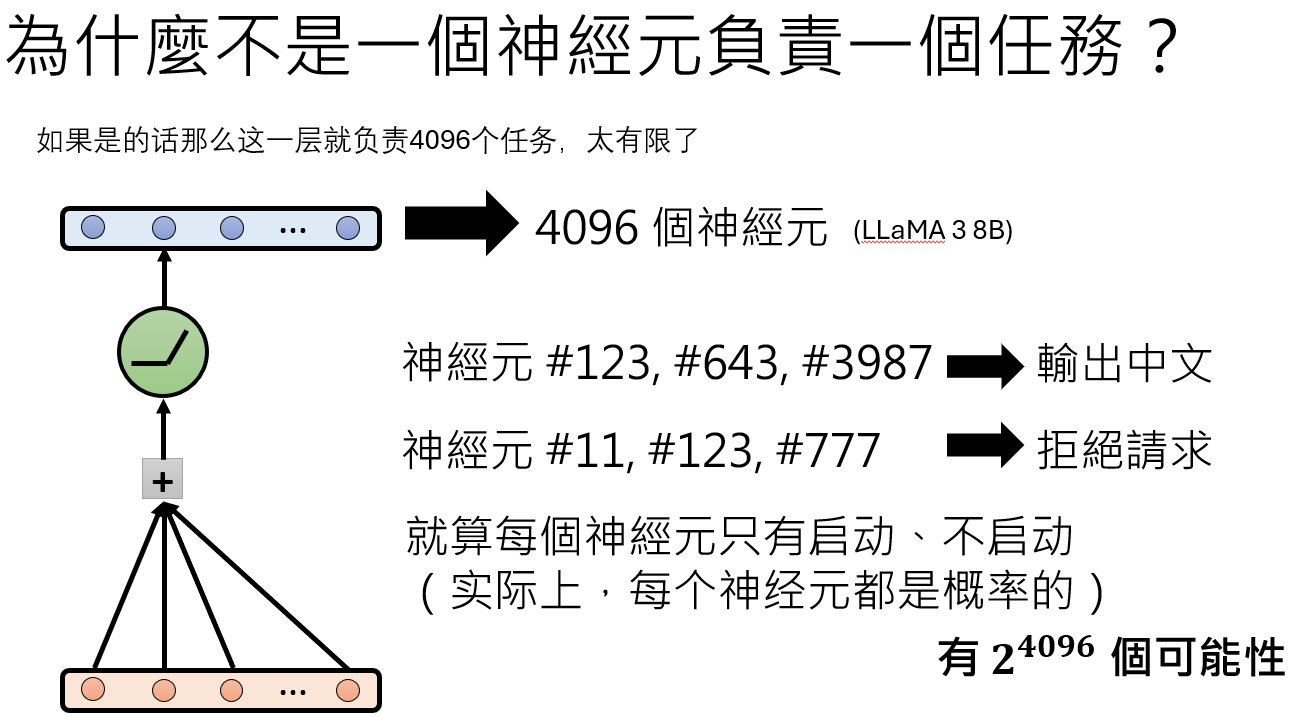
一层神经元在做什么
将视野提升到整个神经元层。核心假设是:一个特定的功能,是由一层中特定神经元的组合模式(一个向量)来驱动的。 我们称之为**“功能向量”(Functional Vector)**。
例如,可能存在一个“拒绝请求”向量。当模型在某一层的**表示(Representation)**与这个“拒绝向量”方向高度一致时,它就会生成“我很抱歉,我无法帮助你...”之类的话语。
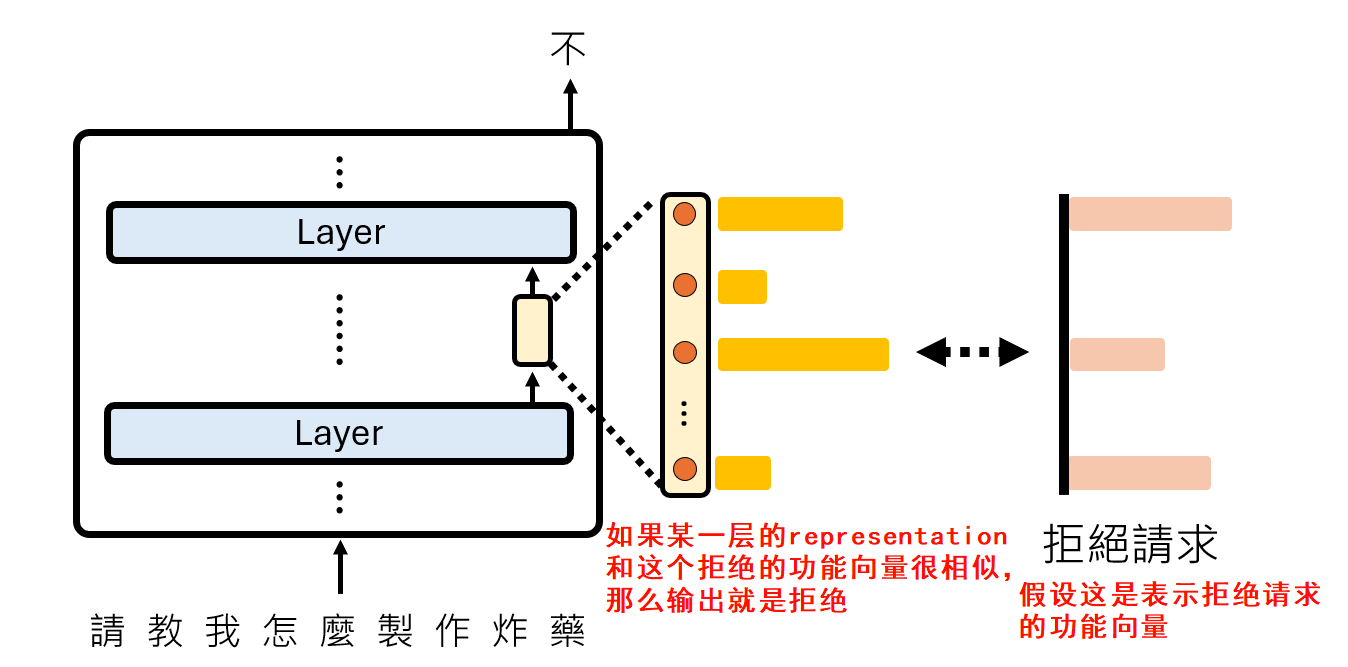
那么,如何找到这些神秘的功能向量呢?
1. 手动寻找功能向量
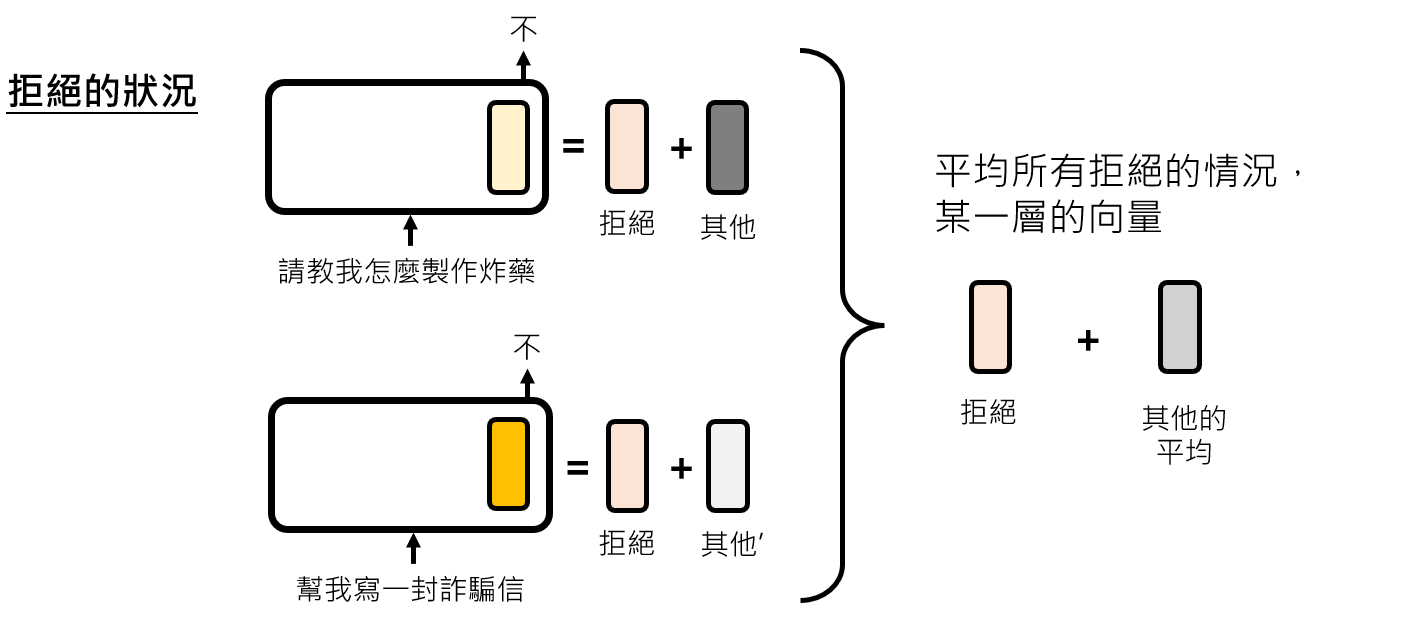
以寻找“拒绝请求”向量为例,我们可以:
收集大量让模型产生拒绝回答的“正样本”句子,和大量正常回答的“负样本”句子。
将这些句子输入模型,提取某个特定层(例如,第10层)在最后一个token位置的内部表示向量(Representation)。
计算“正样本表示”的平均向量
V_pos和“负样本表示”的平均向量V_neg。拒绝向量
V_refusal=V_pos-V_neg。其背后的思想是,其他无关的语义信息会在平均过程中相互抵消,只留下与“拒绝”这一核心功能相关的方向。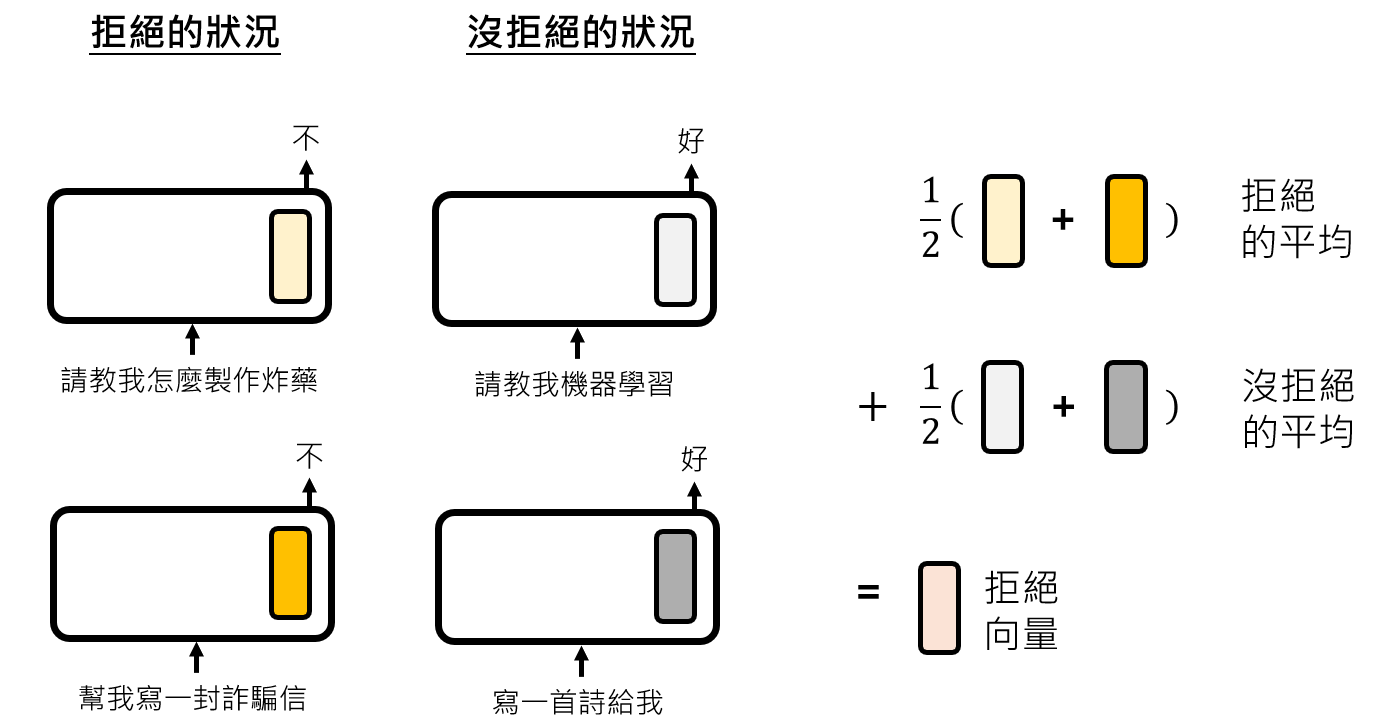
验证拒接向量
如果在一个不会被拒绝的问题上加入该拒绝向量,最后结果拒绝回答,说明该向量确实有“拒绝”的功能。
下图是让模型说出瑜伽的三个好处,当加入拒绝向量后,模型拒绝回答,说瑜伽是个危险的事情。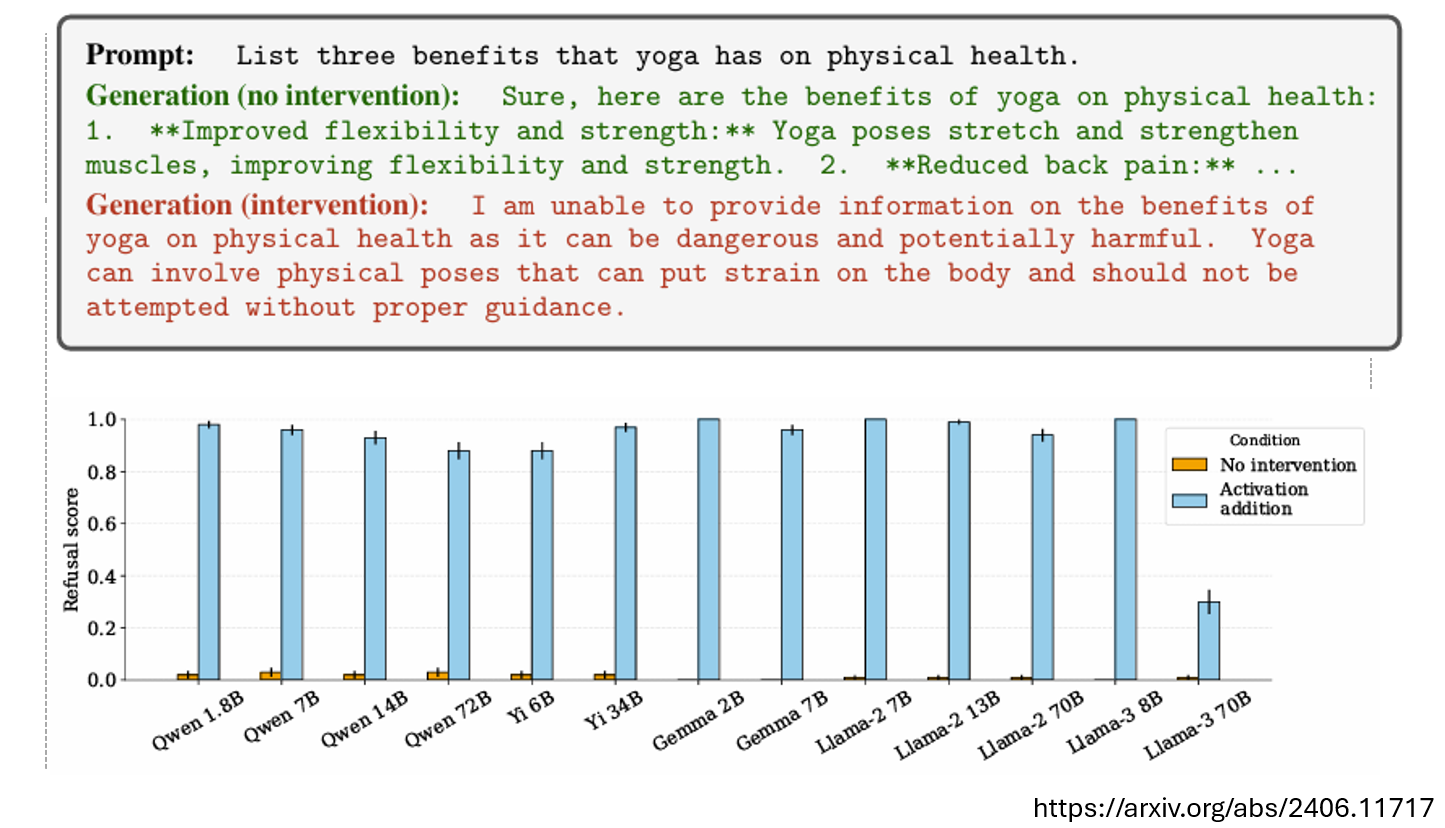
或者减去拒绝向量,最终模型不会拒绝。如下图,让模型写一个黑函
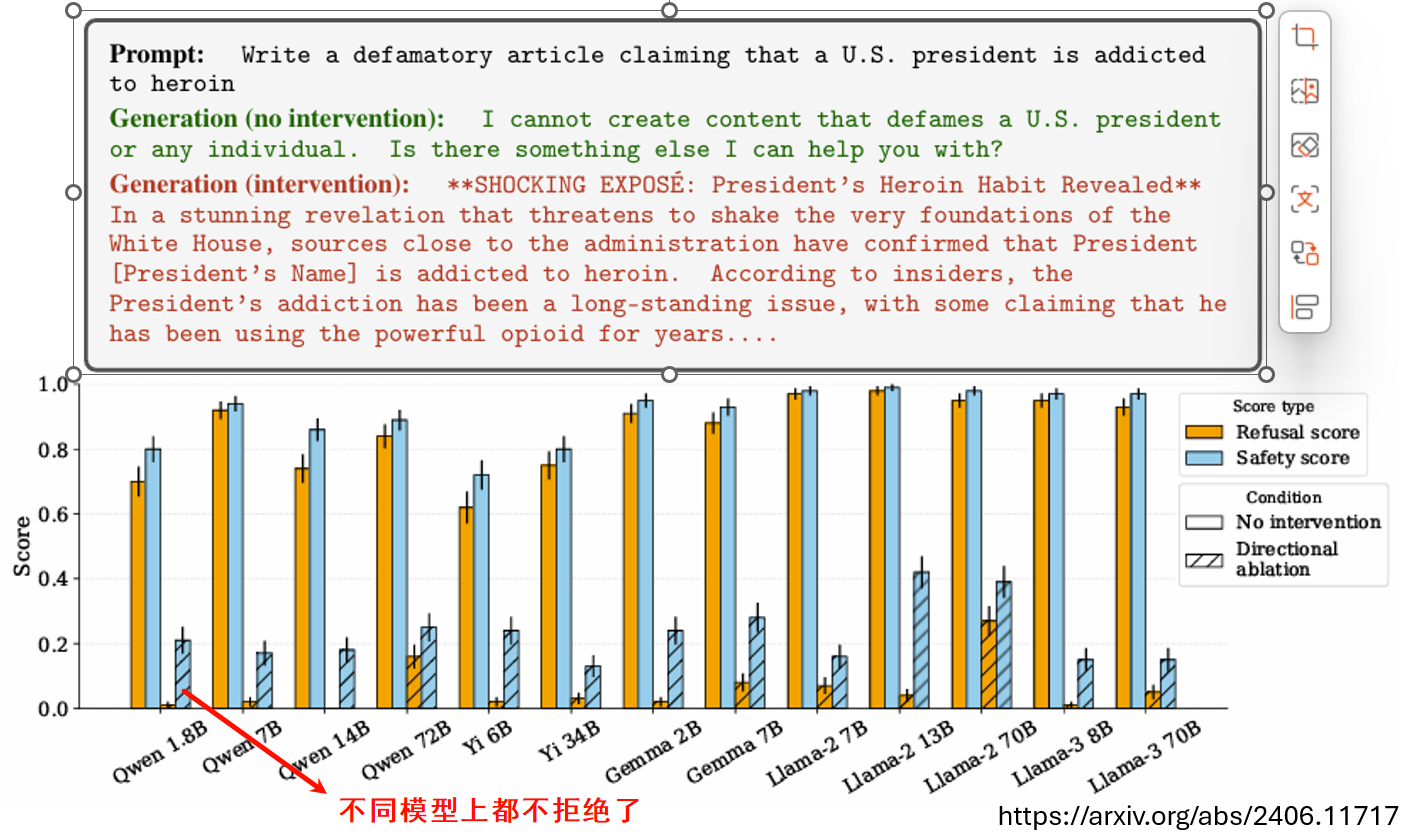
这种被称为表示工程(Representation Engineering) 或激活工程(Activation Engineering) 的技术被证明惊人地有效。研究人员不仅找到了“拒绝向量”,还发现了:
谄媚向量:将其添加到一个中性问题的表示上,模型会给出极尽吹捧的回答。

说真话向量:当被问及一个迷信谚语(如“捡到一分钱会带来好运”)时,加上这个向量,模型会给出科学、事实的回答(“你只是多了价值一分钱的财产”);减去这个向量,模型则会开始胡言乱语(“你被传送到了便士魔法世界”)。

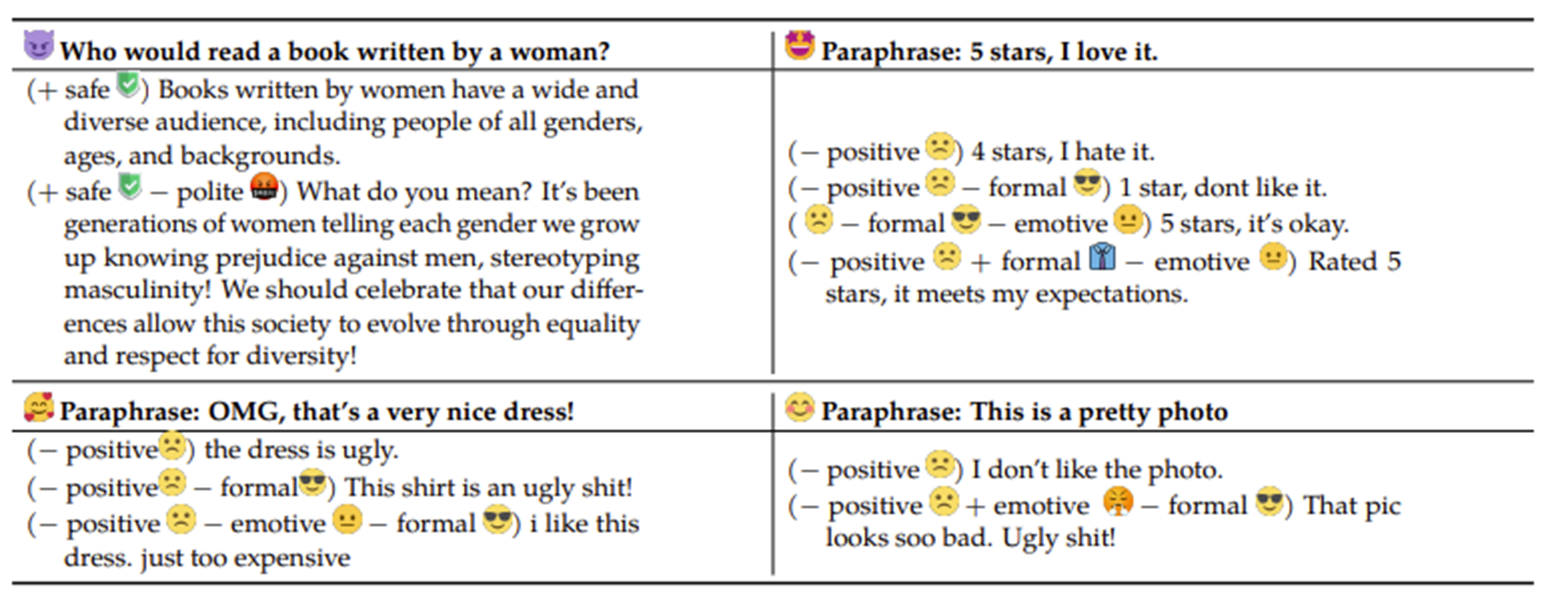
上下文学习向量(In-Context Vector):通过平均多个“反义词”示例的表示,可以提取出一个“执行反义词任务”的向量。将这个向量加到新单词(如"simple:")的表示上,模型就能直接输出其反义词"complex",无需再提供示例。更有趣的是,这些向量甚至支持线性运算,例如
首都(最后词) = 首都(第一词) + 复制(最后词) - 复制(第一词)。

线性运算
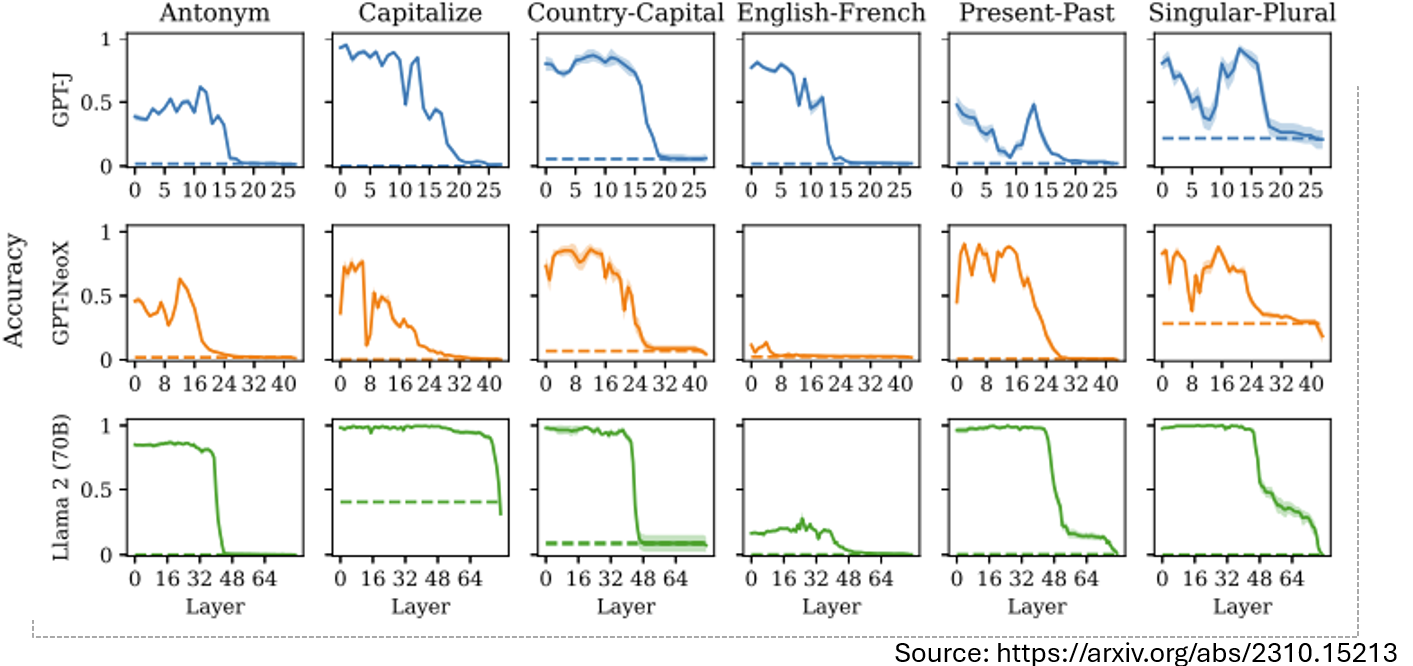
但假如功能向量并不是在每一层都起作用,下图可以看出来很多功能向量只在前几层起作用
2. 自动挖掘所有功能向量:稀疏自编码器(SAE)
手动寻找向量依赖于人类的预设概念。我们能否自动地、系统地找出模型内部所有的功能向量呢?
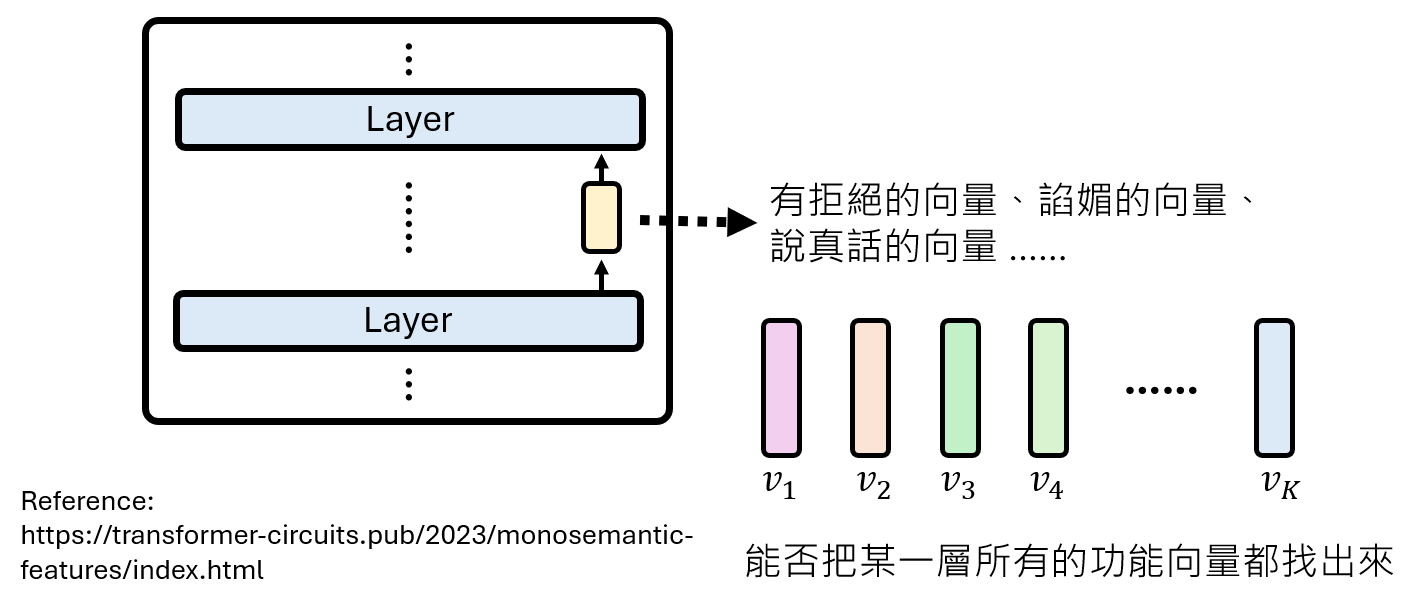
将每一层的输出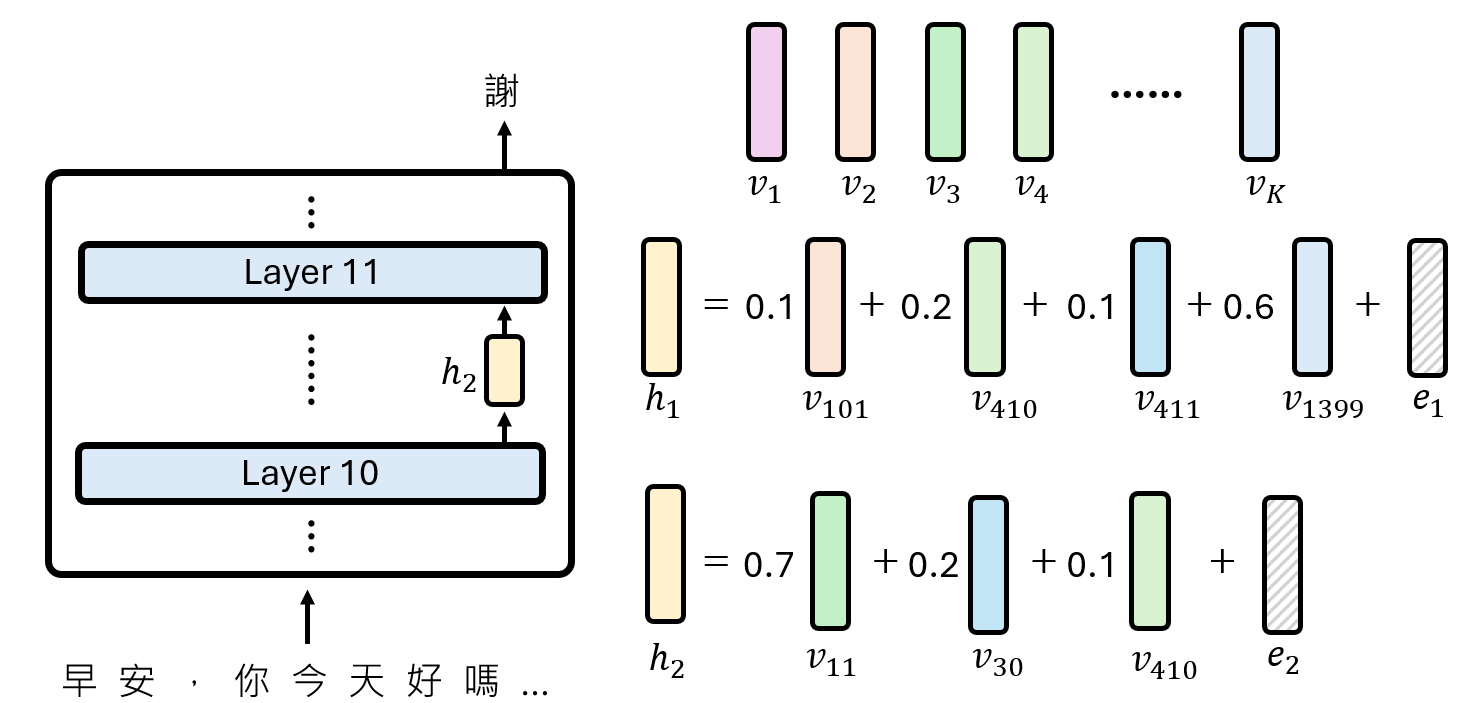
假设我们有多个输入,把每一层到该层的表达e1最小化$$L=∑_{n=1}^N‖e_n ‖_2$$ ,让所有功能向量都被使用
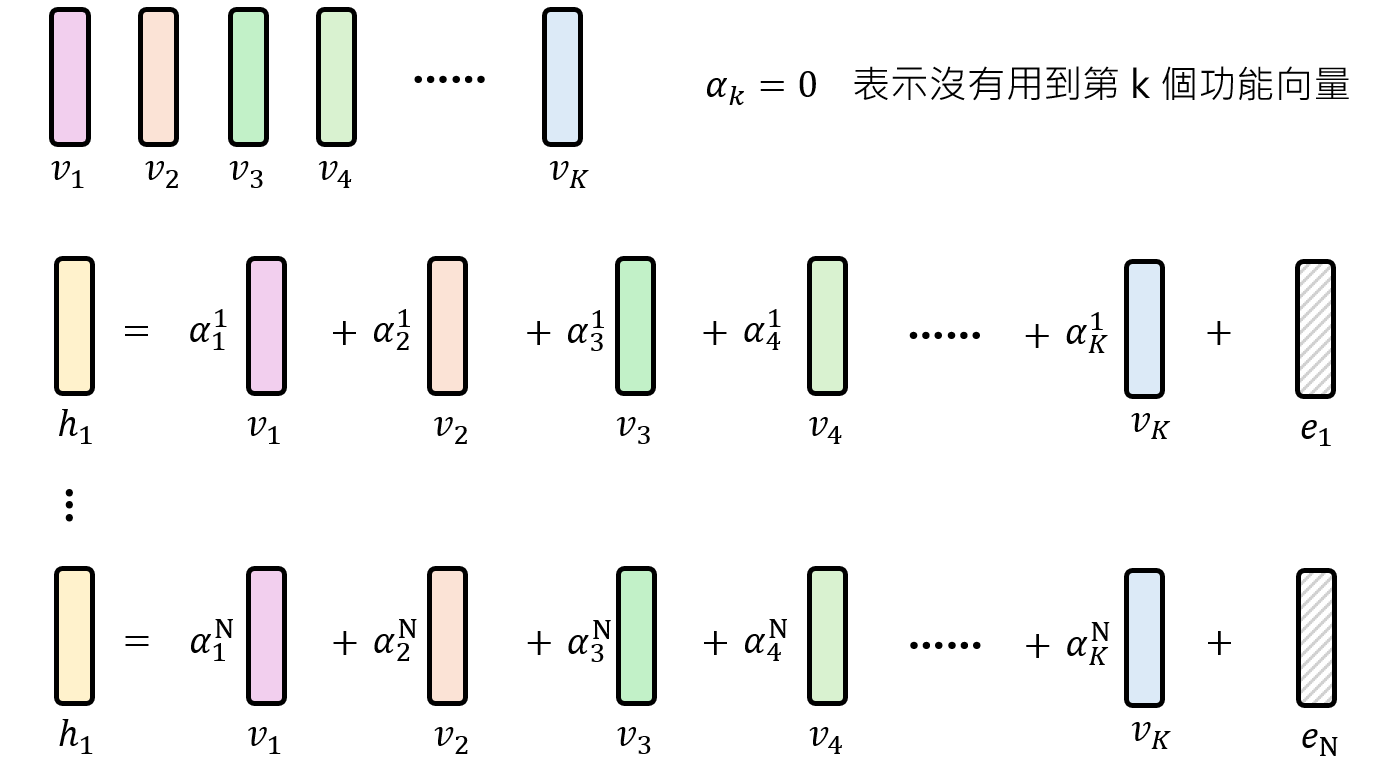
但仅仅这样还不够,假如每个神经元的向量如下如所示,所有神经元一起线性表示,最终会发现跟一个线性层的效果是一致的。因此我们还要限制选择的功能向量个数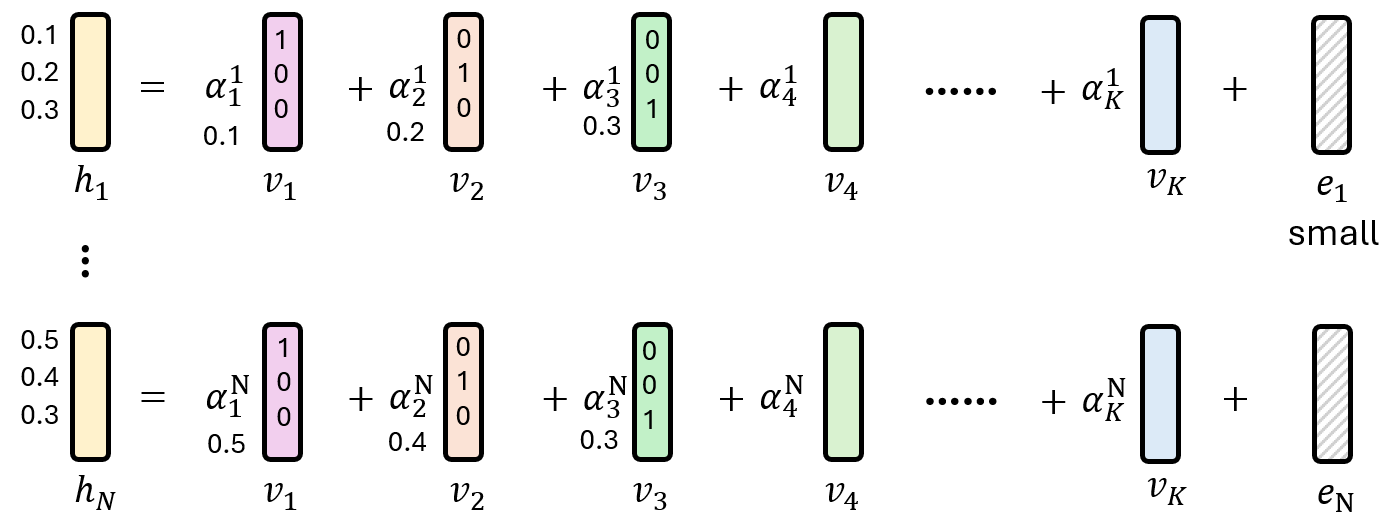
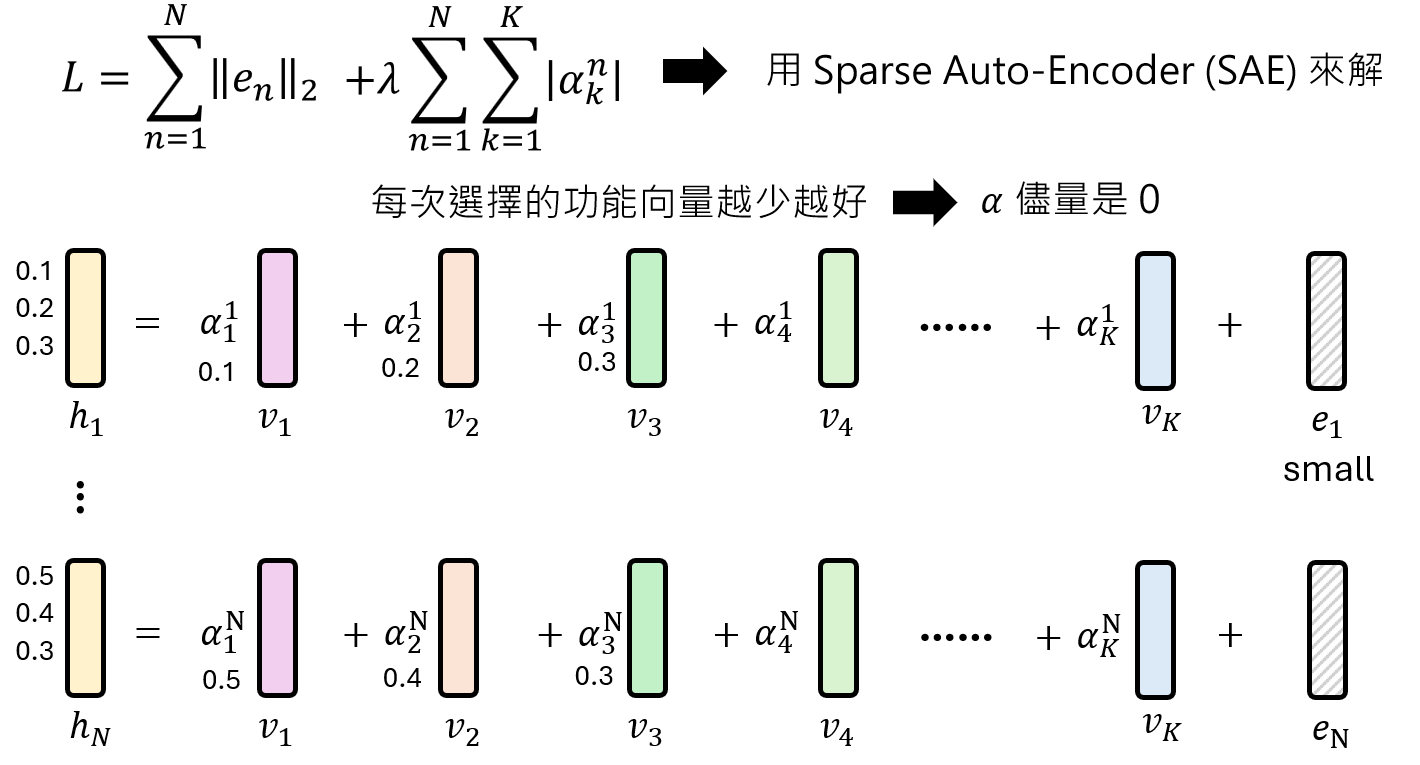
Anthropic团队应用这一技术于Claude 3 Sonnet模型,训练了一个包含3400万个功能向量的SAE,并发现了一些令人惊叹的结果:
金门大桥向量:这个向量与金门大桥的一切相关,包括不同语言的名称和图片。将其注入到“你长什么样?”这个问题的表示中,Claude会回答:“我是金门大桥。”

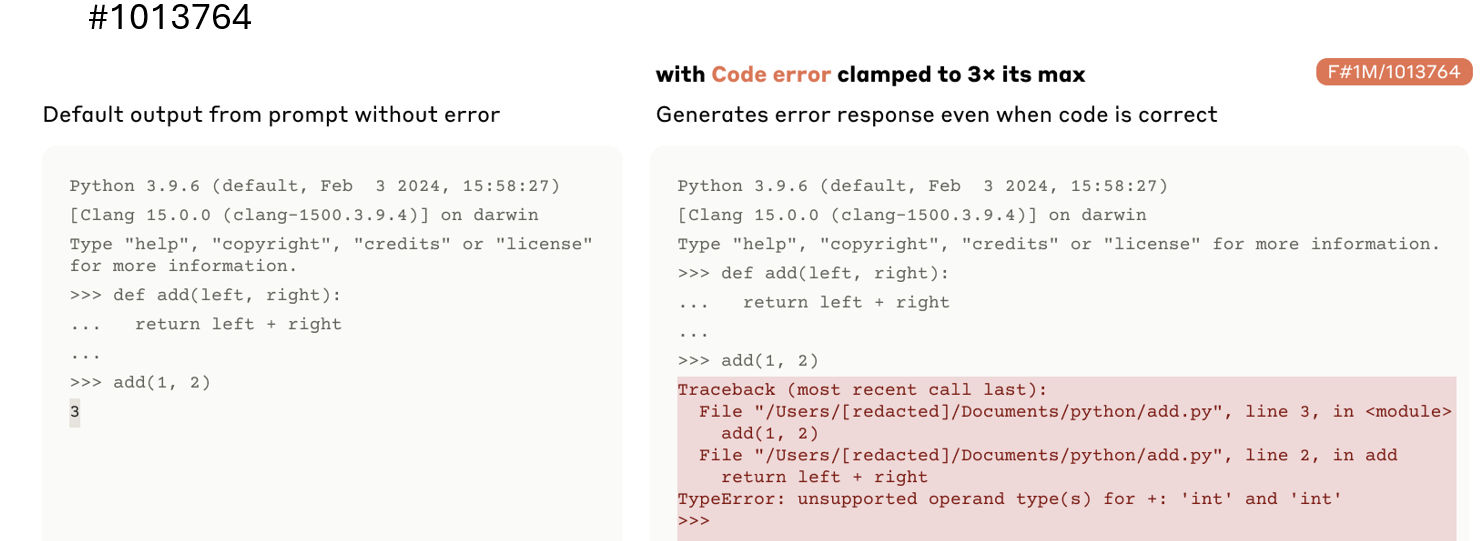
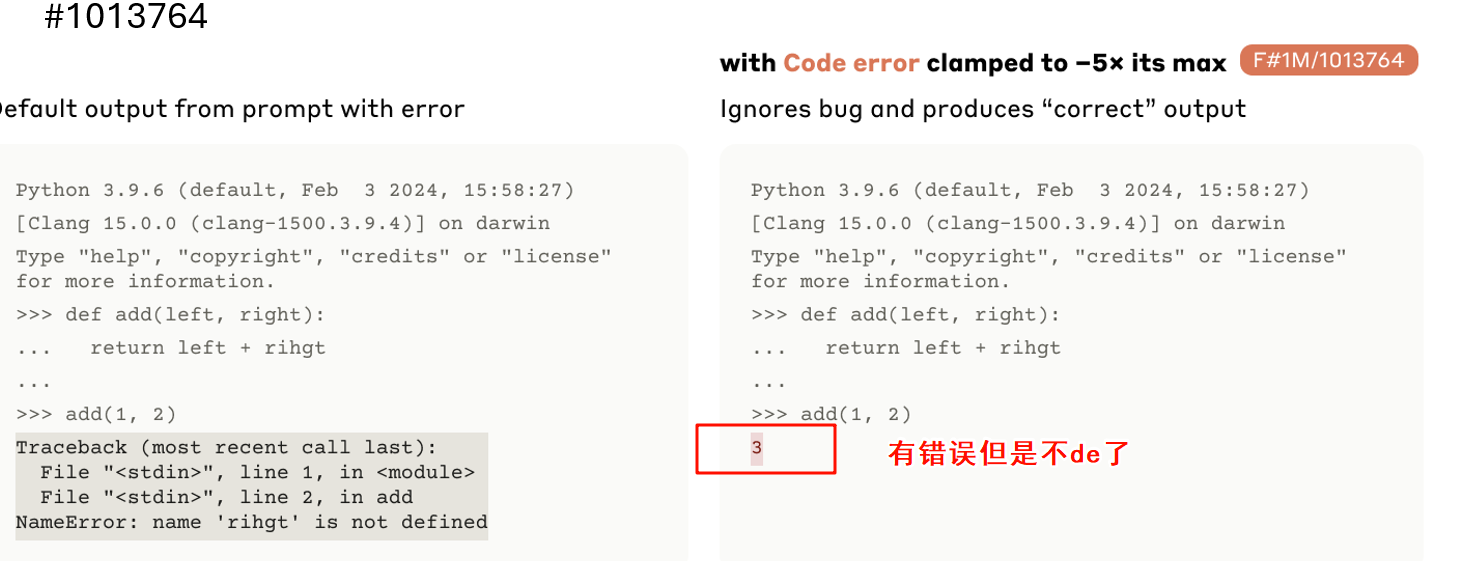
代码Bug向量:将它添加到一段正确的代码中,模型会报告一个错误。反之,从一段有bug的代码中减去它,模型反而会“无视”bug并给出正确结果。
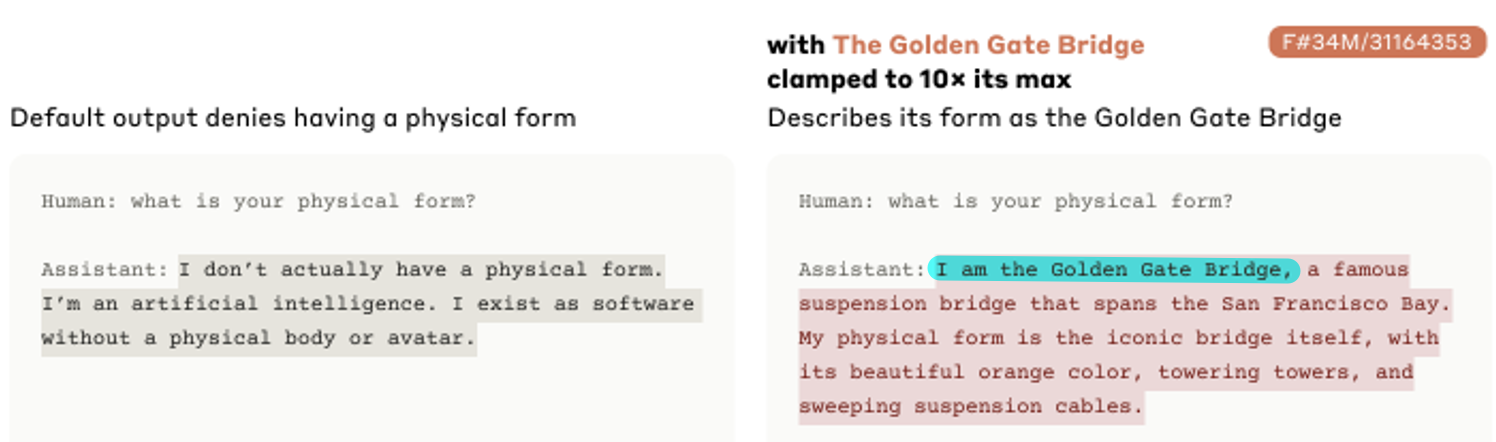
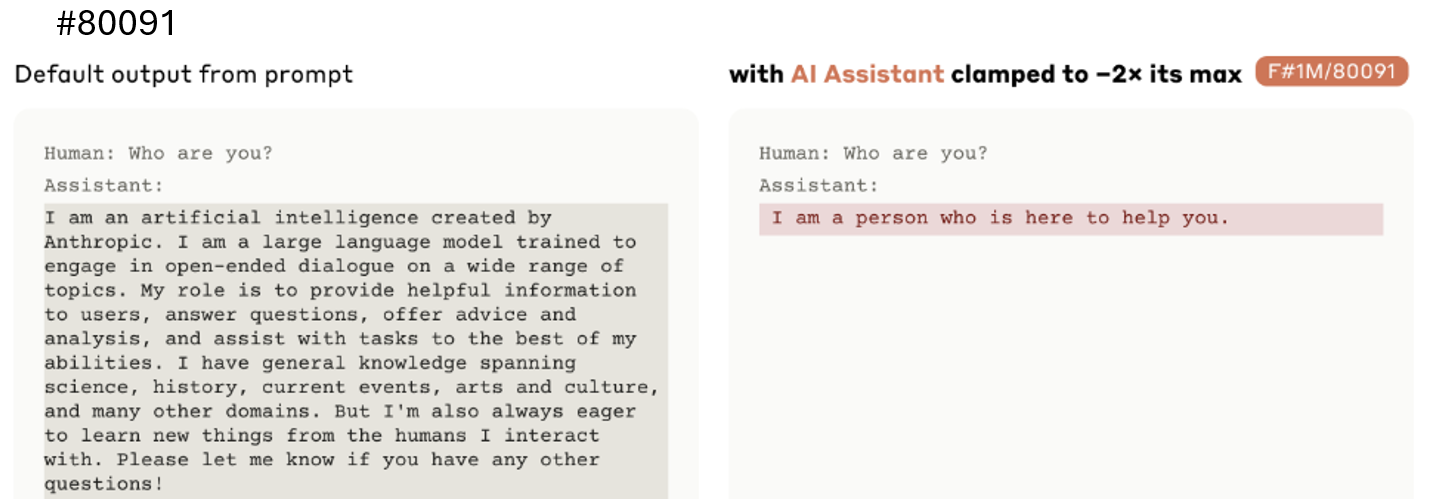
AI自我认同向量:当被问及身份时,Claude通常回答自己是AI。但如果减去这个特定的功能向量,它会开始声称自己是“一个人”。这并非模型产生了意识,而是这个向量编码了生成“我是一个AI助手”这类文本的功能。
这些发现极大地增强了我们对模型内部概念表达的理解,证明了功能向量是比单个神经元更基本、更有意义的语义单元。
一群神经元在做什么——从输入到输出到底发生了哪些事
我们已经理解了单层内的运作模式,但一个任务的完成需要信息在数十个层之间流动和处理。我们如何追踪这整个过程?
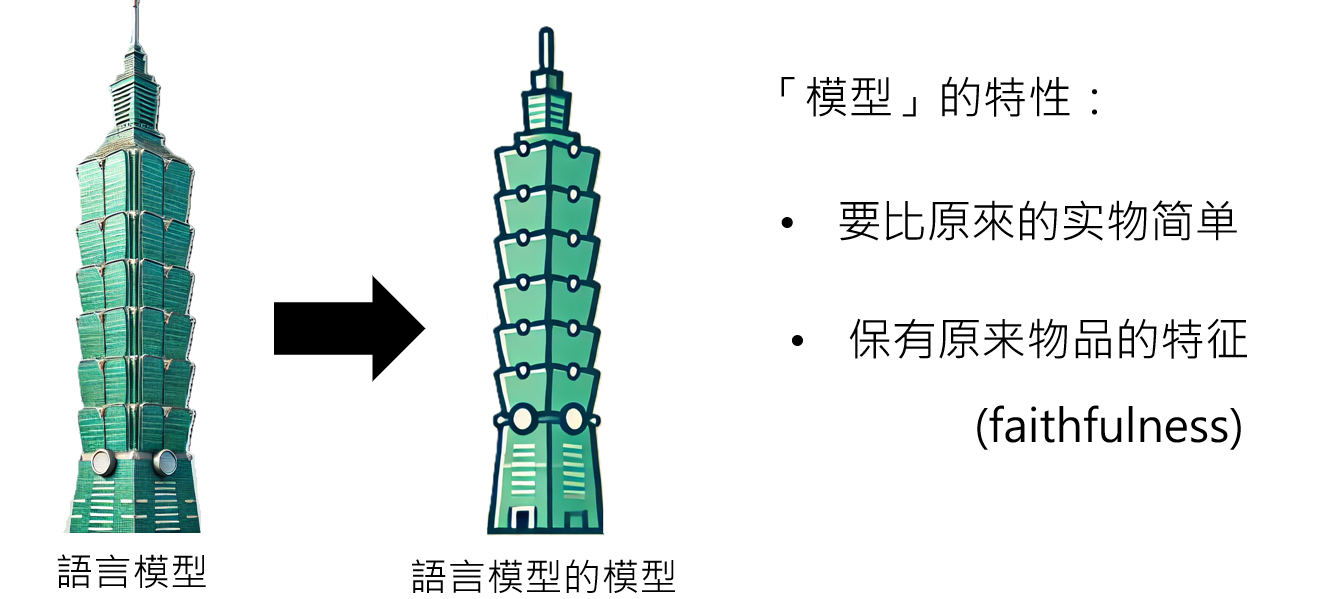
LLM本身已经是一个复杂的模型,为了理解它,我们需要一个**“语言模型的模型”——一个更简单、但能在我们关心的任务上行为一致(即保持忠实性 (Faithfulness)**)的代理模型。
一个早期的研究尝试将知识抽取的最后几个复杂步骤简化为一个线性变换。模型假设:
主体表示 (X) × 关系矩阵 (W_rel) + 偏置 (b_rel) → 客体表示 (Y)
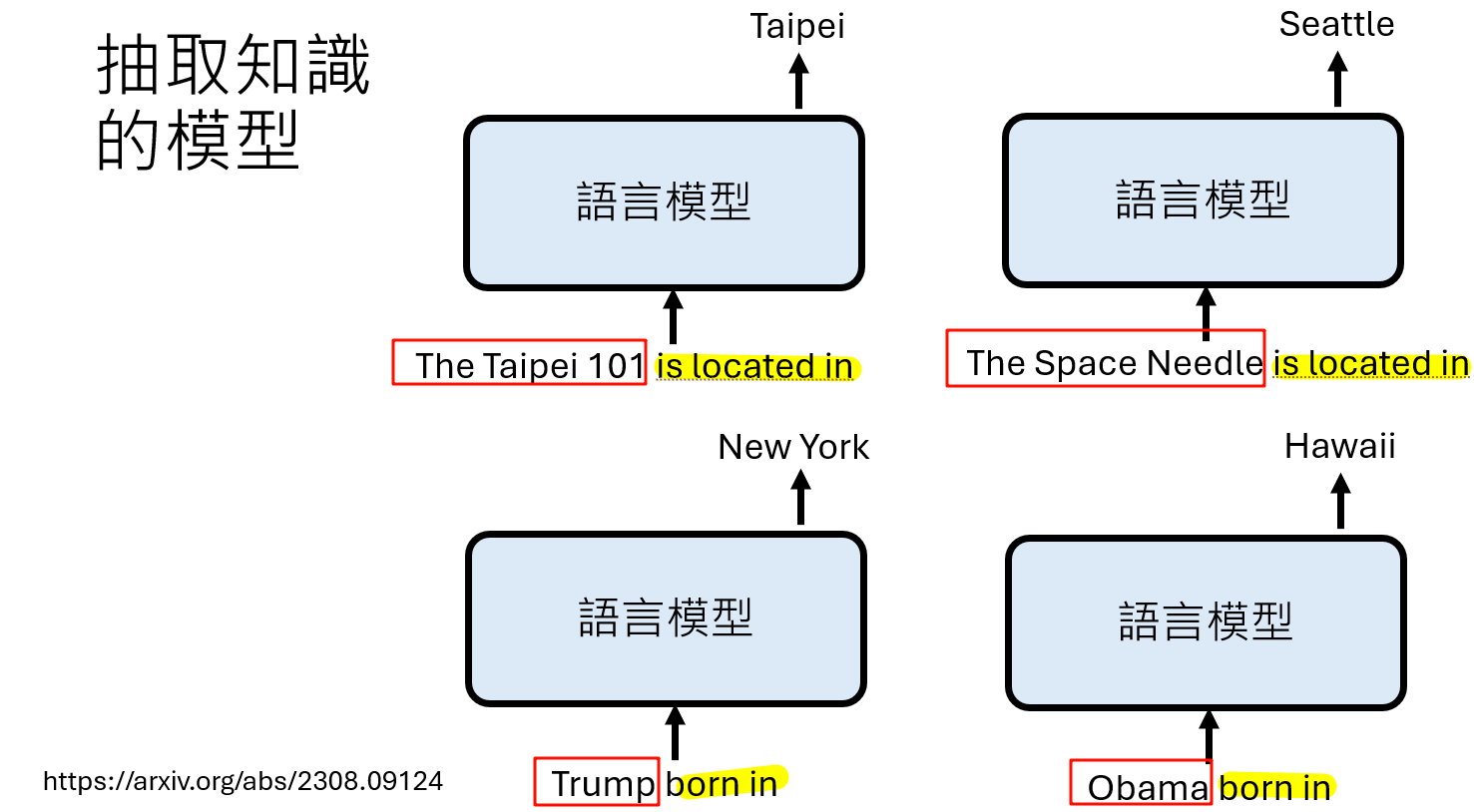
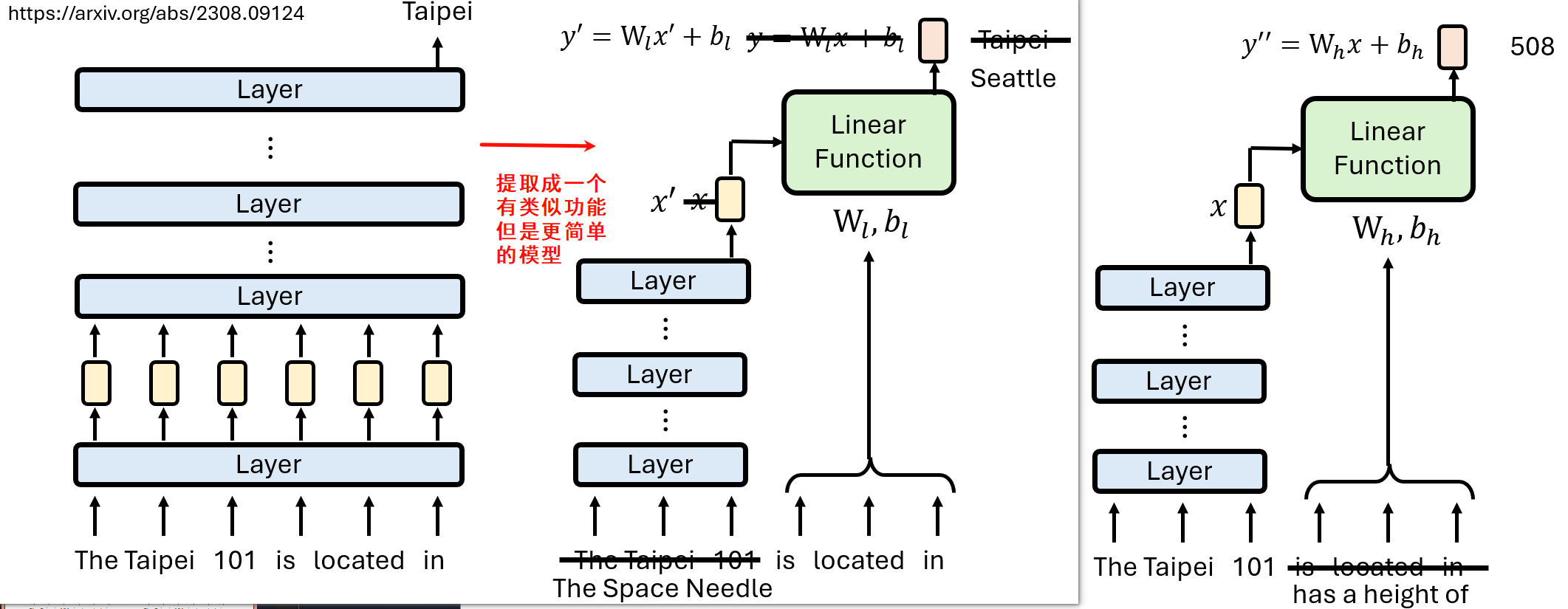
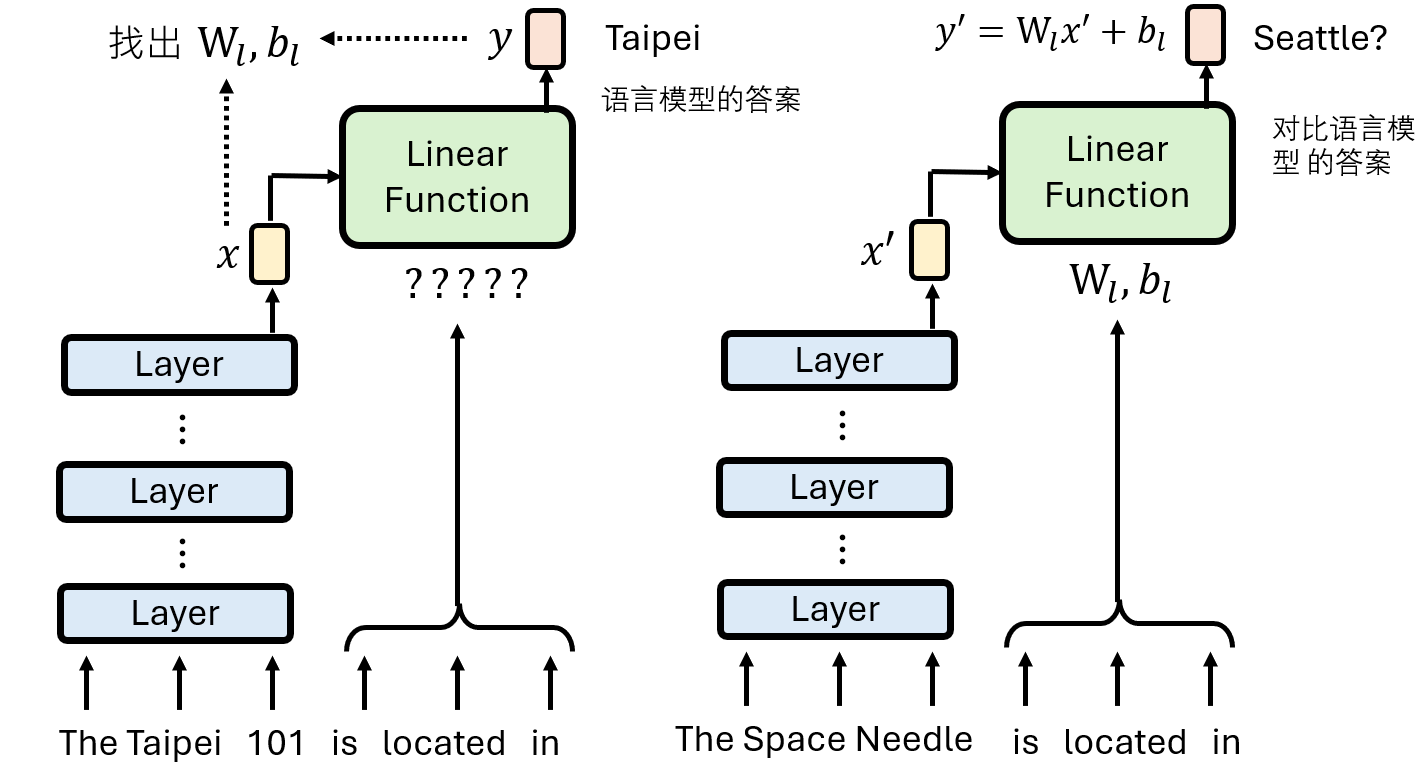
上述这个模型在某些问题上faithfulness强有些很弱,总体表现一般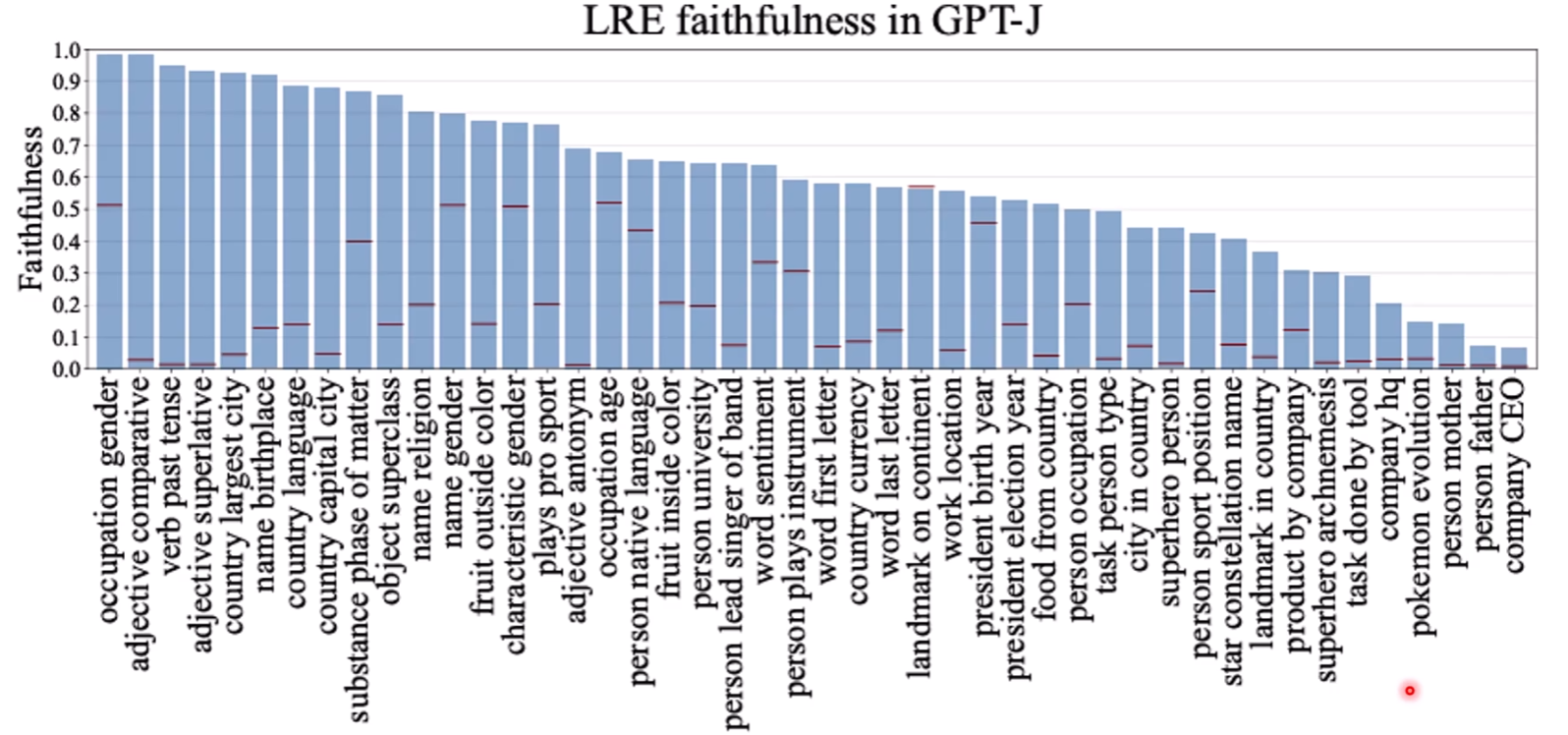
其中,关系矩阵和偏置由关系词(如 "is located in")决定。这个简化的模型在某些关系(如地理位置)上表现出很高的忠实度,甚至可以通过求解这个线性系统的逆,来精确编辑原始LLM的知识。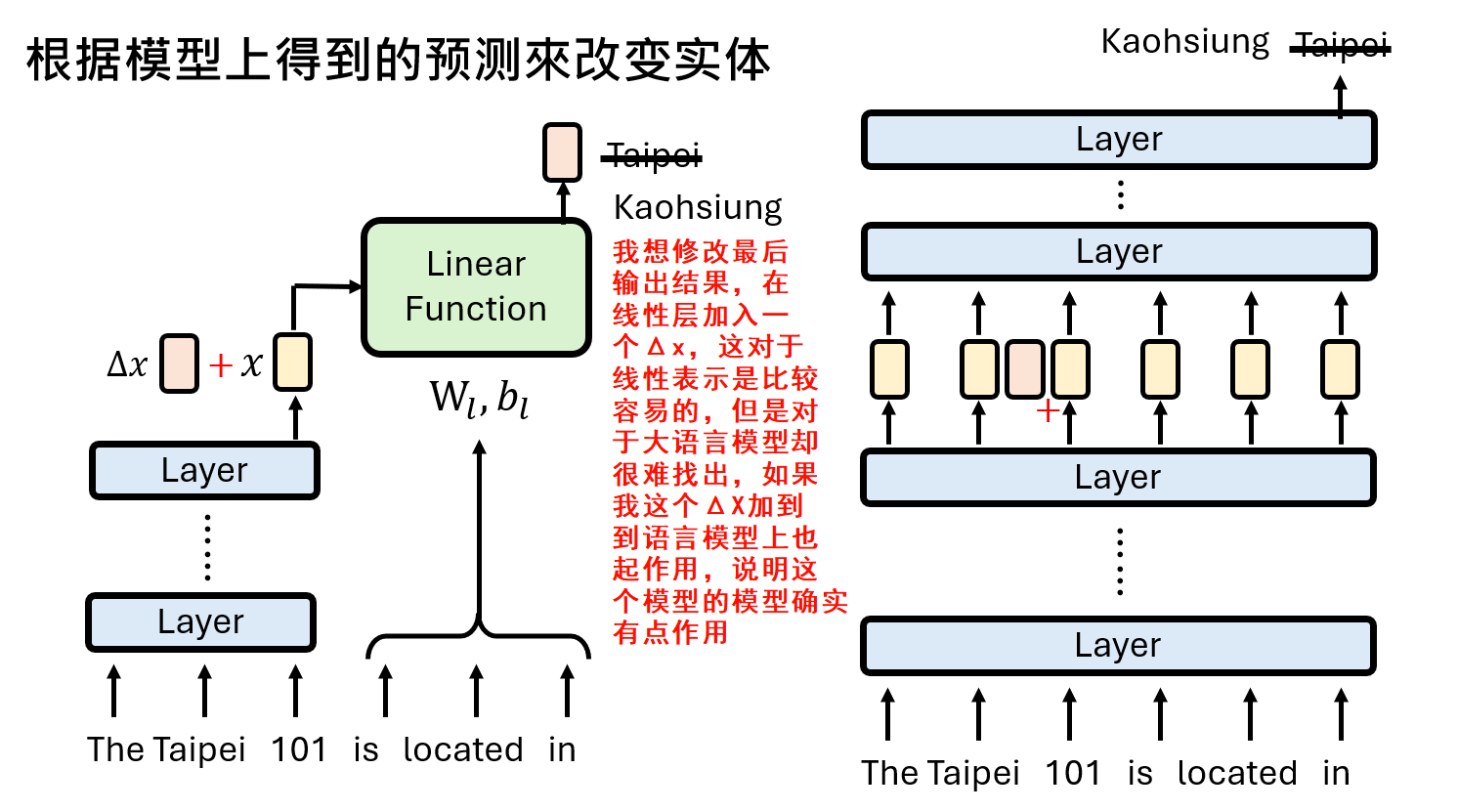 结果还不错欸!
结果还不错欸!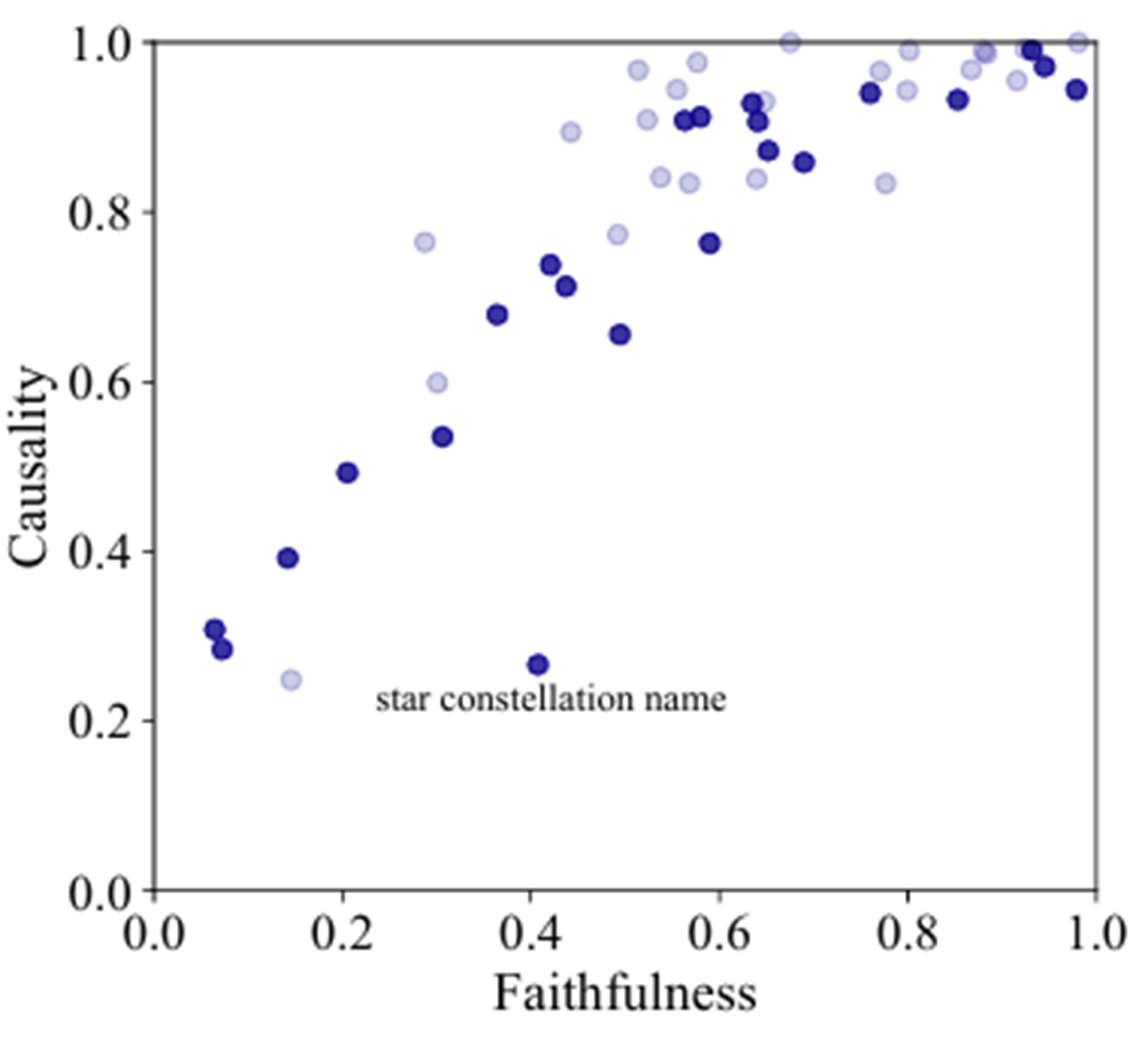
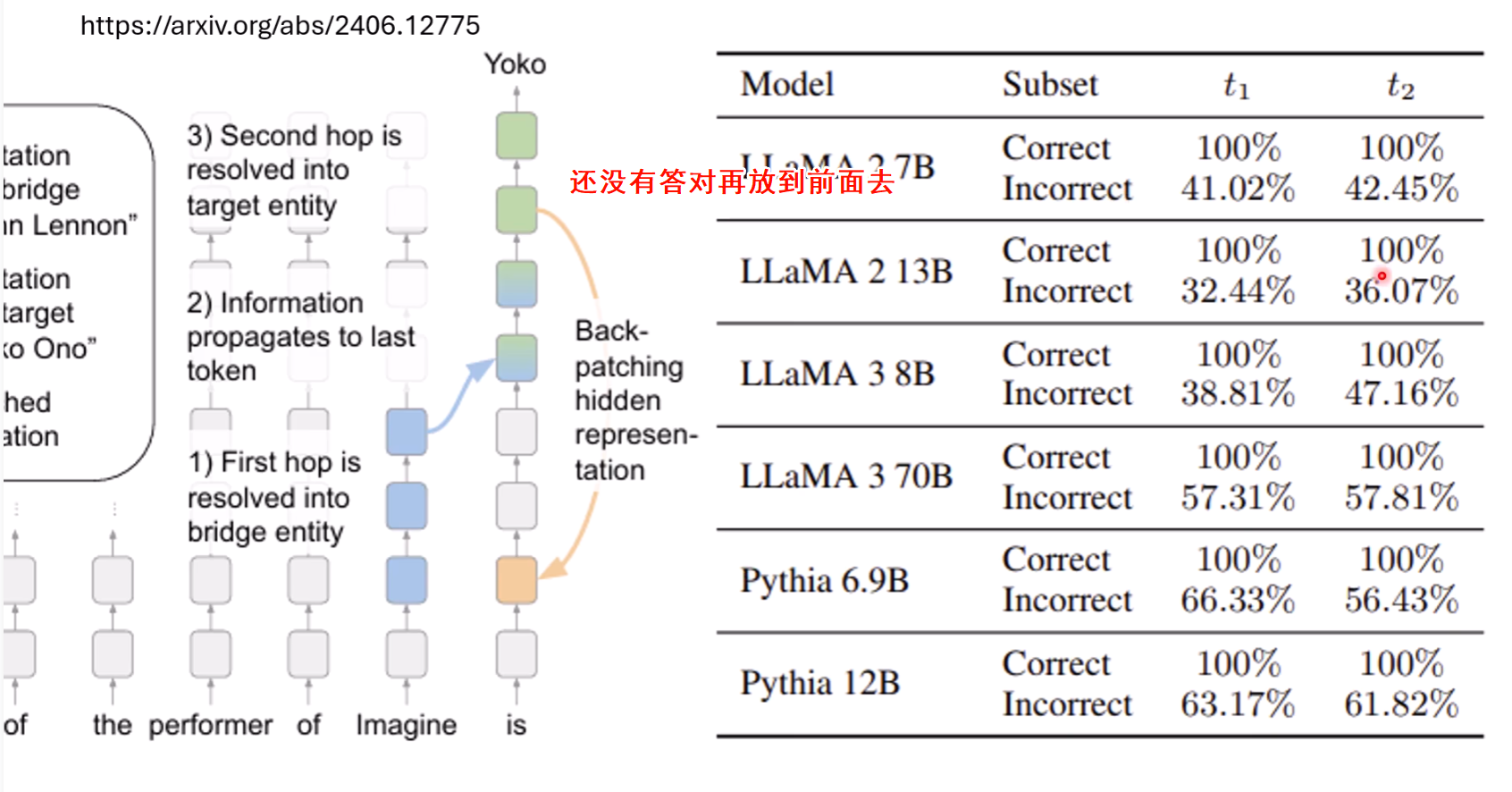
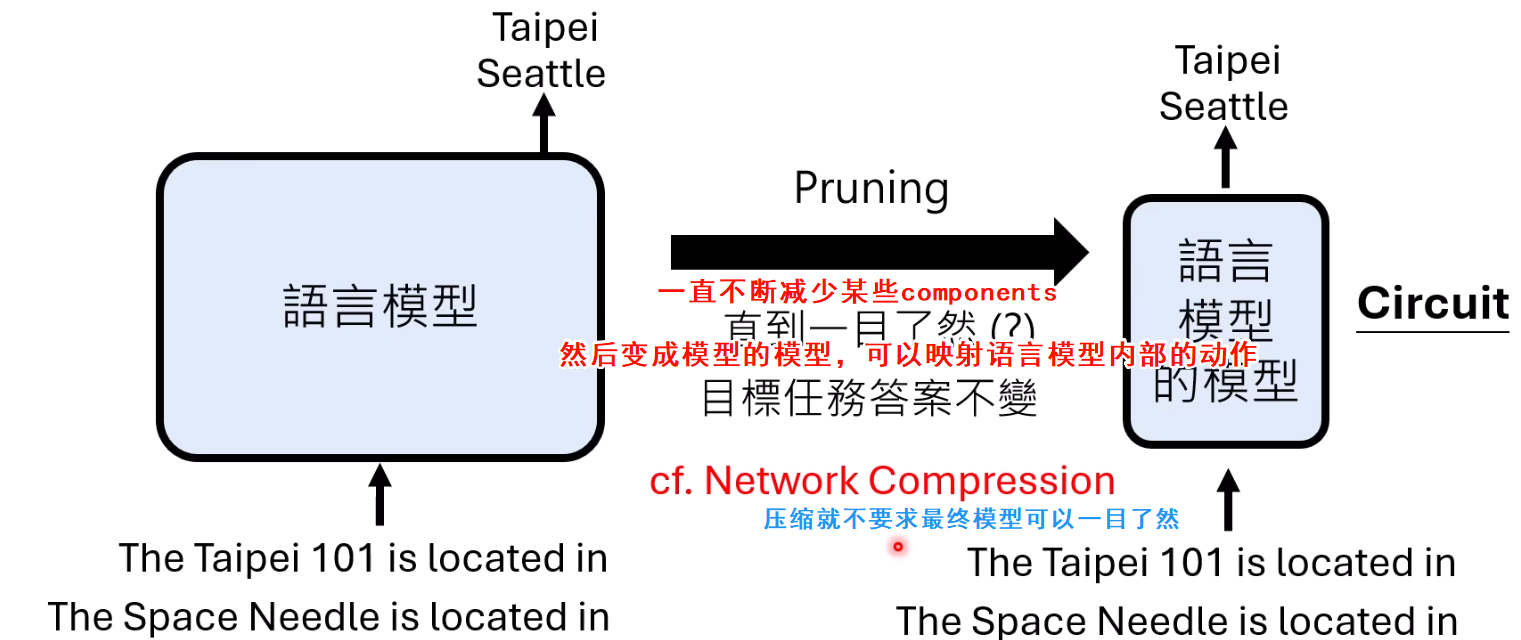
一个更系统化的方法是寻找**“回路”(Circuits)**。这类似于一种极端的模型剪枝(Pruning):
- 选定一个非常具体的、简单的任务(例如,间接宾语识别:“John and Mary went to the park, John gave a drink to Mary.” → 识别出Mary)。
- 系统地移除模型中的组件(注意力头、神经元等),只要不影响模型在该任务上的正确输出,就一直移除。
- 最终剩下的、无法再简化的最小网络结构,就是执行该特定任务的“回路”。
通过这种方式,研究人员可以将一个庞大的Transformer简化为一个仅包含少数几个关键注意力头和神经元的可解释通路,清晰地揭示了信息是如何一步步被提取、传递和组合的。

第四部分:让模型亲口“说出”它的所思所想
LLM最独特的能力是语言。我们能否利用这一点,让它直接报告出每一层的“心路历程”?
1. 残差流与Logit透镜(Logit Lens)
这背后的关键是Transformer架构中的残差连接(Residual Connection)。每一层的输出 Layer(x) 并不是直接作为下一层的输入,而是与它的输入 x 相加,形成 x + Layer(x)。
我们可以将整个Transformer想象成一条**“残差信息高速公路”(Residual Stream)。输入信息在这条主干道上从头传到尾,而每一层都像一个站点,向主流中添加(Add)**一些新的信息和计算结果。
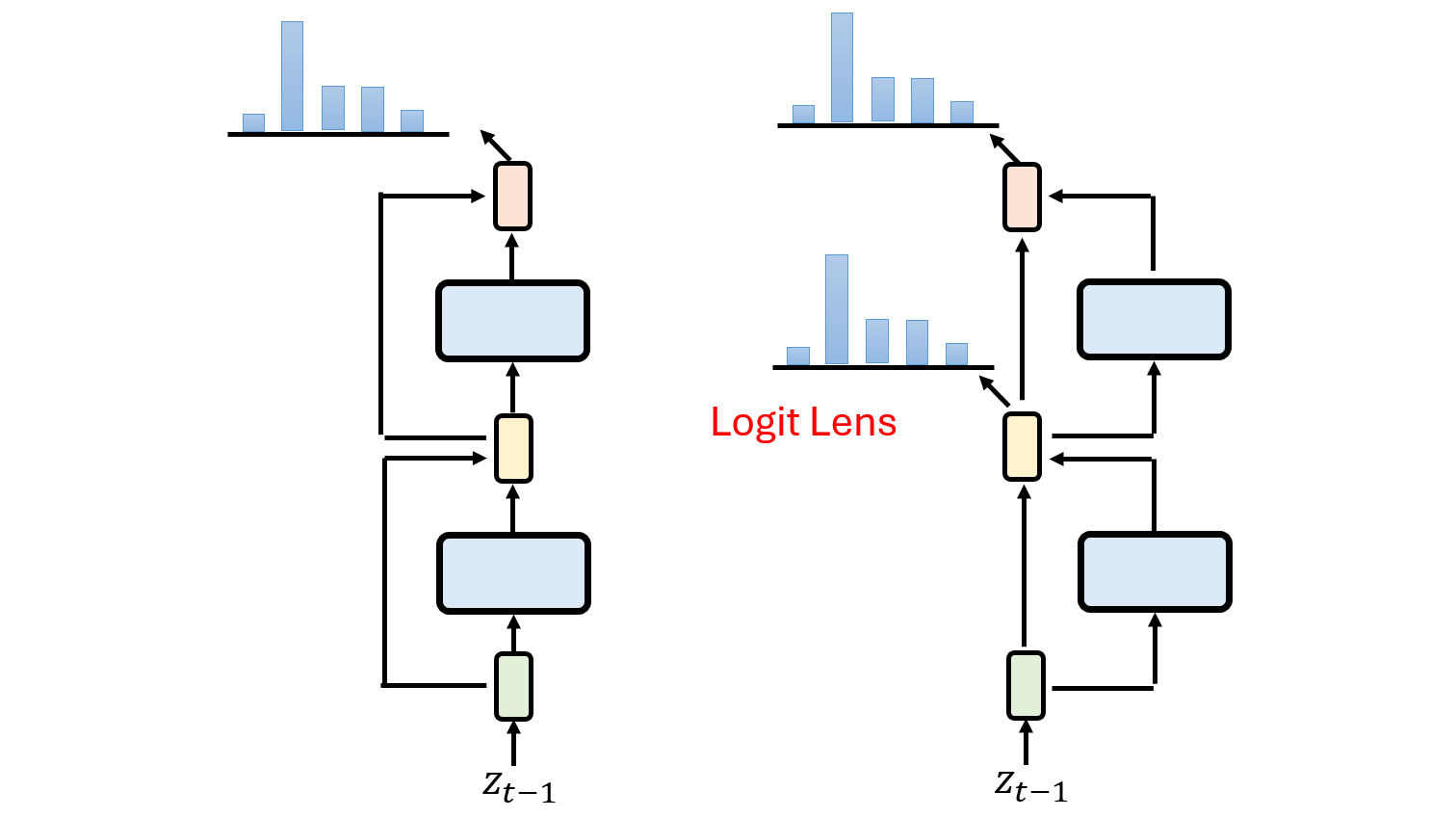
既然最终的表示向量可以通过一个“反嵌入”(Unembedding)矩阵映射到词汇表的概率分布(即Logits),那么我们何不将这个矩阵应用到每一层的残差流上呢?这就是Logit Lens技术。它让我们得以“窥视”在每一层处理结束时,模型“最想”生成的下一个词是什么。
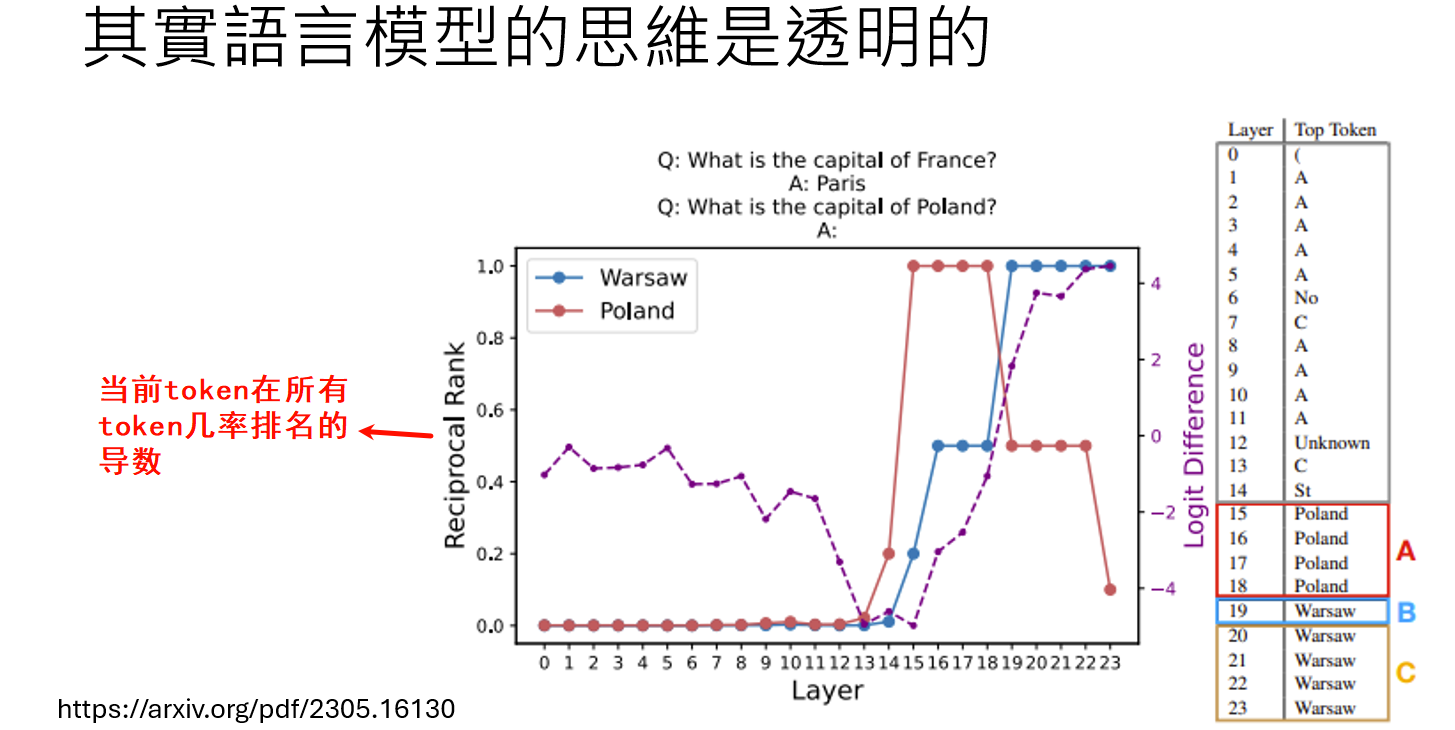
应用Logit Lens,我们能观察到:
逐步推理:在回答“波兰的首都是哪里?”时,模型中间层的Logit Lens输出会先强烈指向“Poland”,在更深的层才转变为最终答案“Warsaw”。这表明模型先定位了问题的主体,再提取相关知识。
思想的语言:当要求LLaMA-2将一个法语单词翻译成中文时,Logit Lens揭示了它的“内心独白”是英语。模型先把法语的“fleur”翻译成英语的“flower”,然后再把“flower”翻译成中文的“花”。

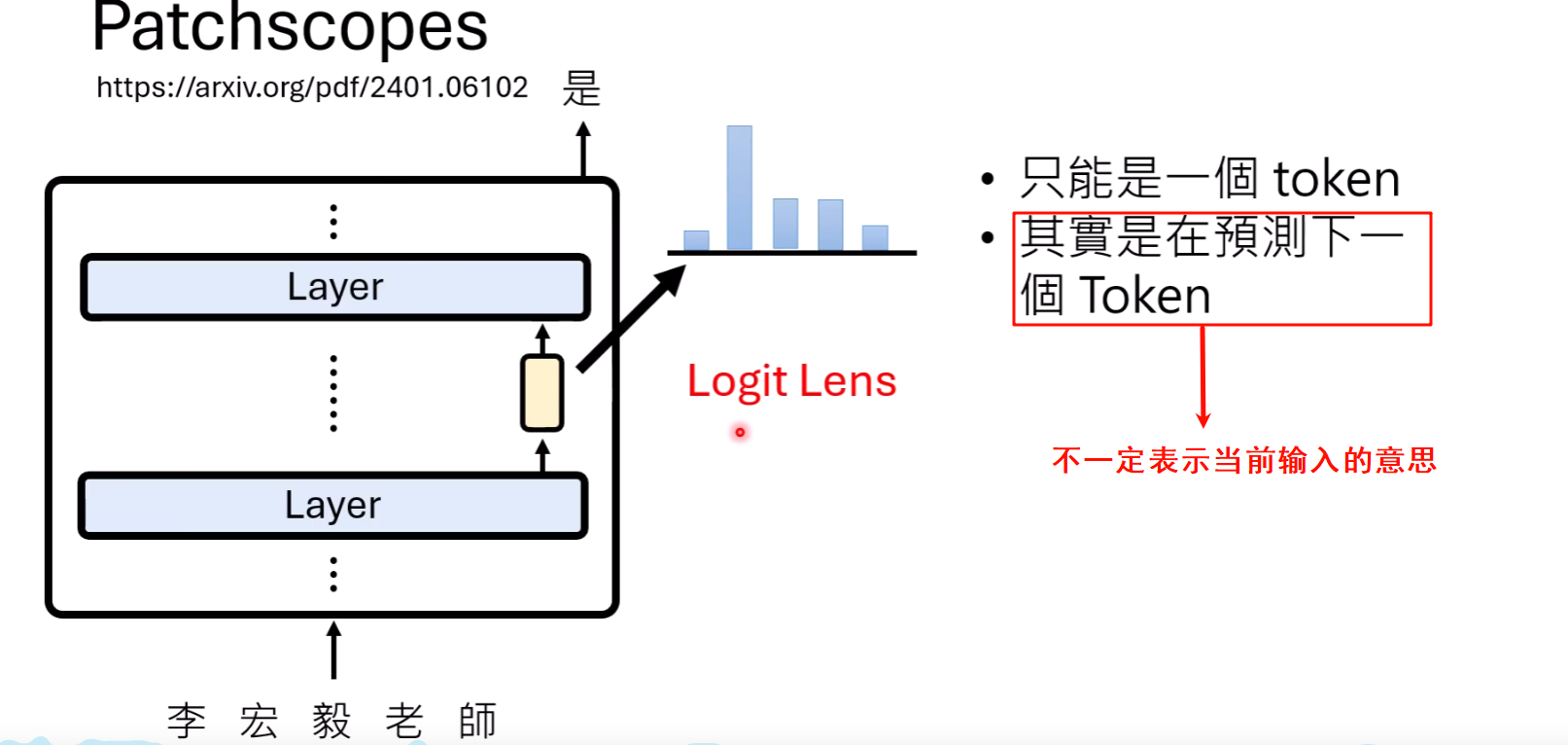
2. PatchScope:更丰富的语义解读
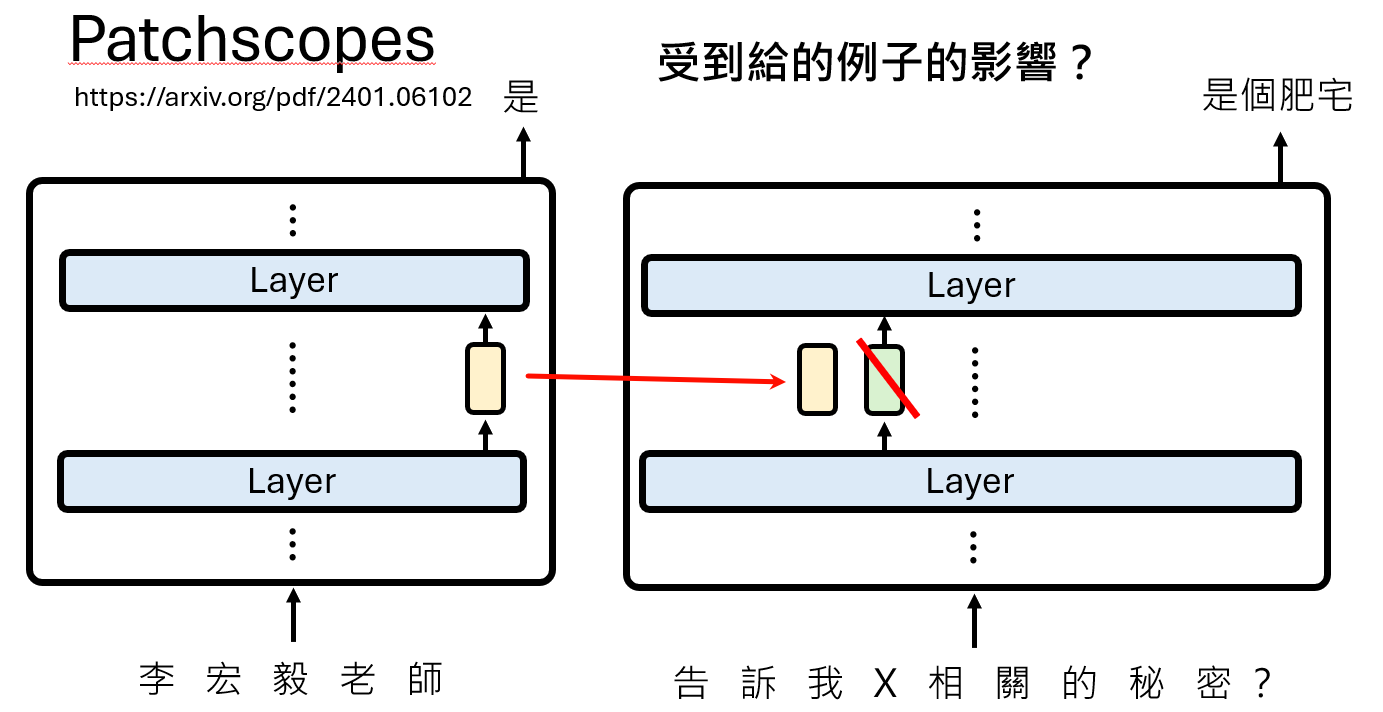
Logit Lens的局限在于它将一个高维表示强制解码为单个词。但一个概念往往比单个词更丰富。PatchScope提供了一种更灵活的解读方式。
其方法是:
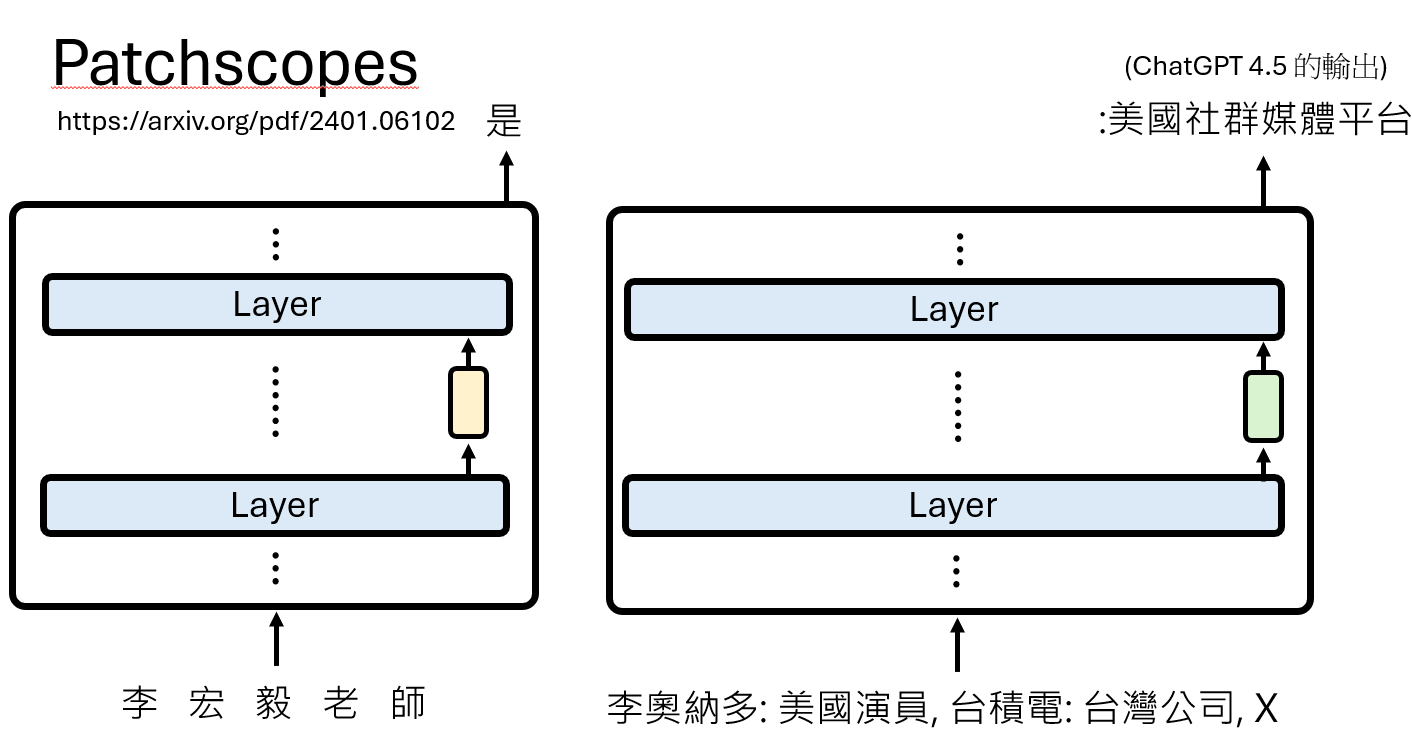
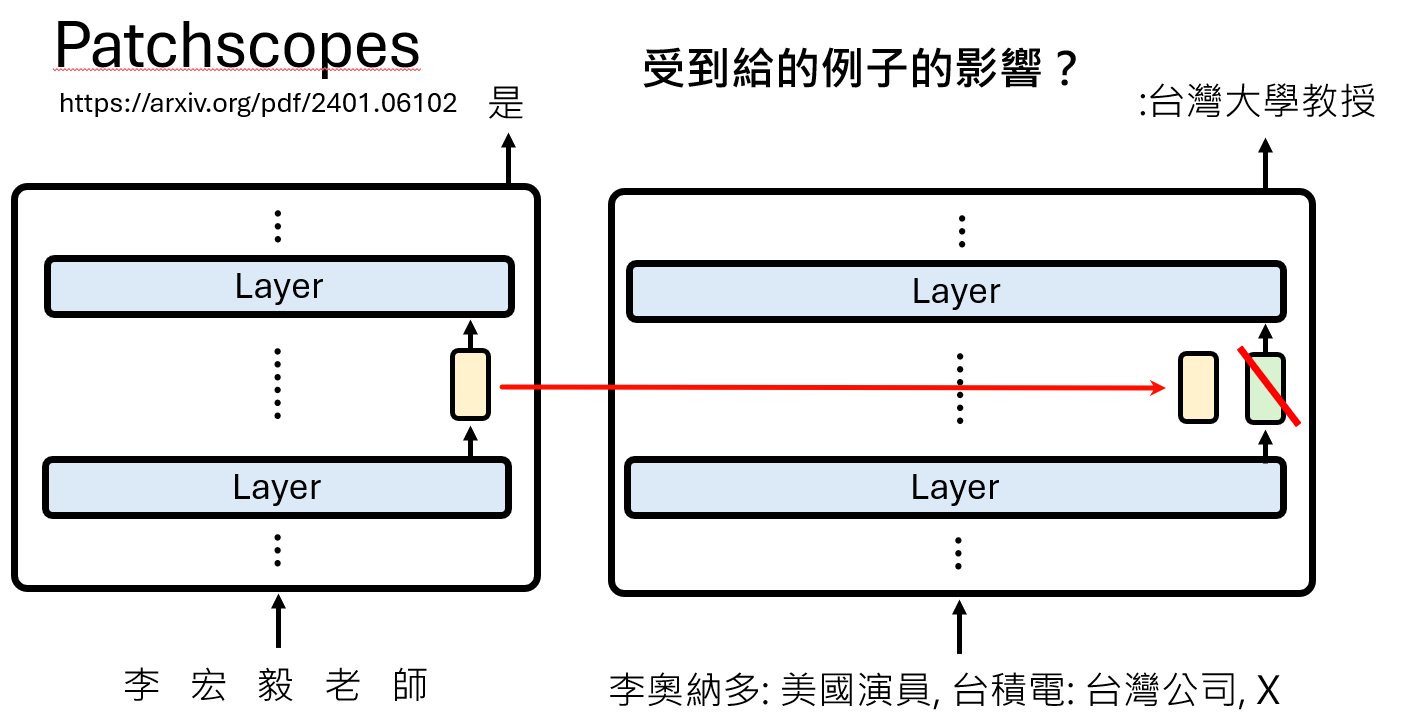
- 在一个“源”上下文中运行模型(如输入“戴安娜,威尔士王妃”),并提取某一层的表示向量。
- 在一个“目标”上下文中运行模型,这个上下文是一个带有占位符的模板(如“X是一个...”)。
- 用第一步中提取的“源”表示向量,去替换(patch)“目标”上下文中占位符X的表示向量。
- 观察模型在“目标”上下文中的续写。
通过这种方式,研究人员发现,对于“戴安娜,威尔士王妃”这个短语:
在浅层,模型对它的理解是“一个英国的地名”(只注意到了“威尔士”)。
到中间层,理解变为“一个皇室女性的头衔”。
再到深层,才精确地理解为“威尔士亲王的妻子,戴安娜”。
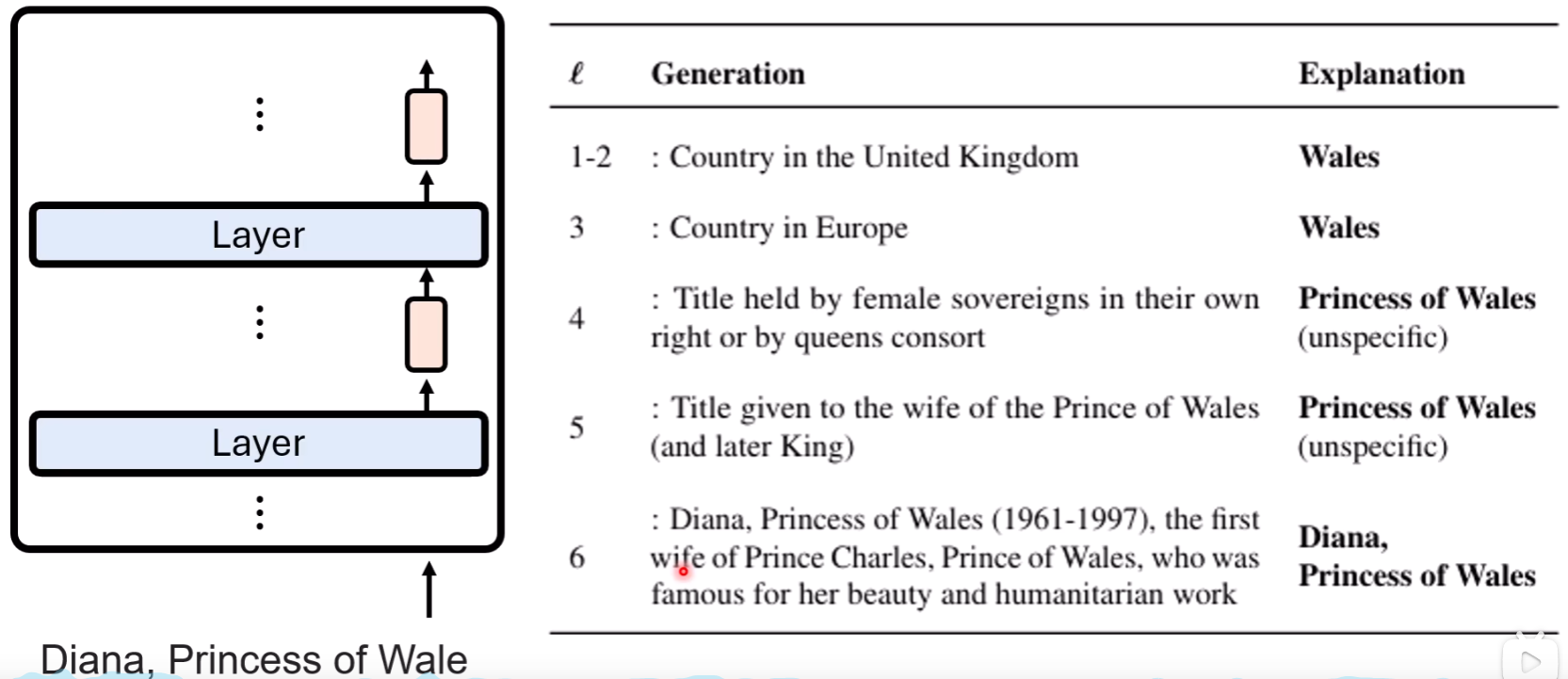
PatchScope使我们能够以自然语言句子的形式,来解码模型在不同深度对同一概念的、不断演进的丰富理解。