温和地走进深度学习
偶然看到的一个关于深度学习的综述,让我受益匪浅。
同时也感受到了什么叫一个高质量综述和高质量组会
温和地走进深度学习_bilibili

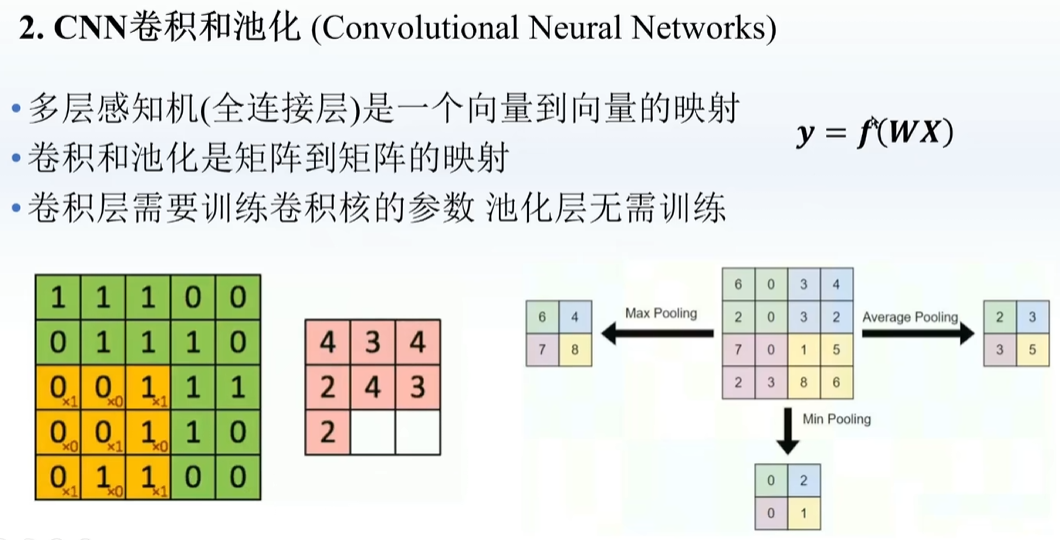
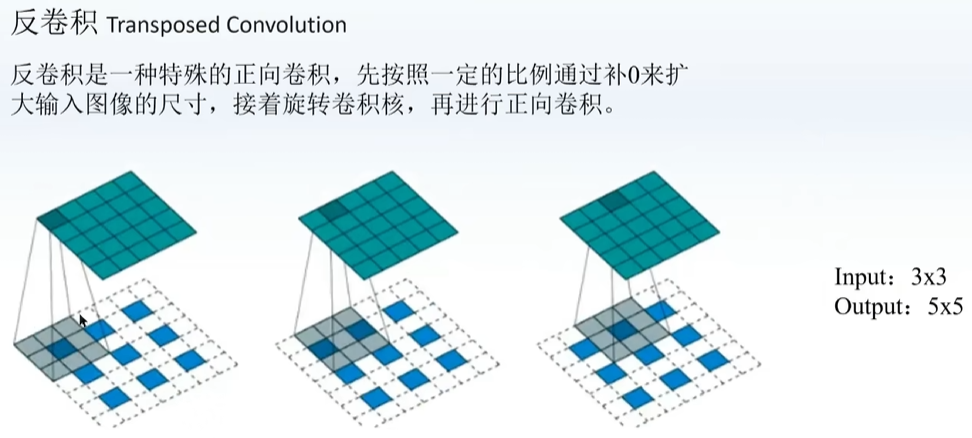
在原本的卷积外面补一圈数(0或其他),再卷积,实现升维
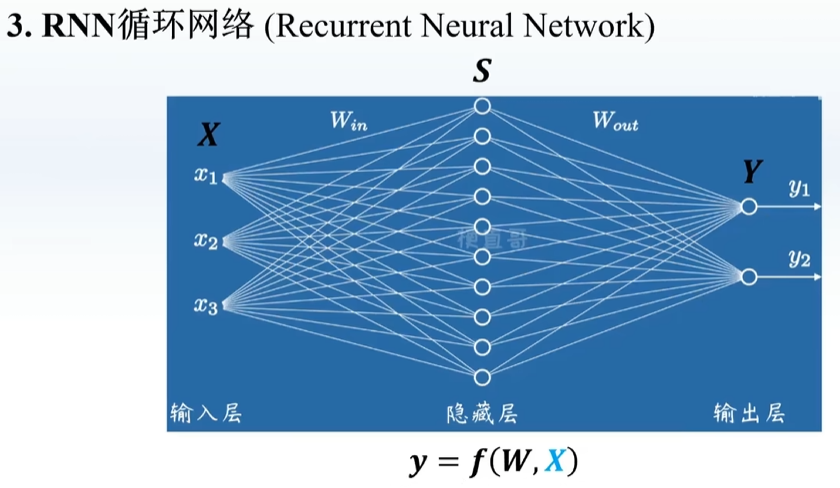
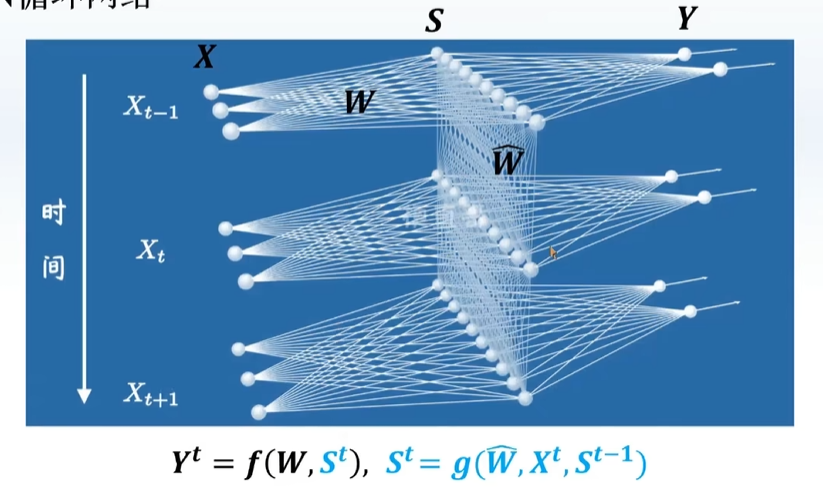
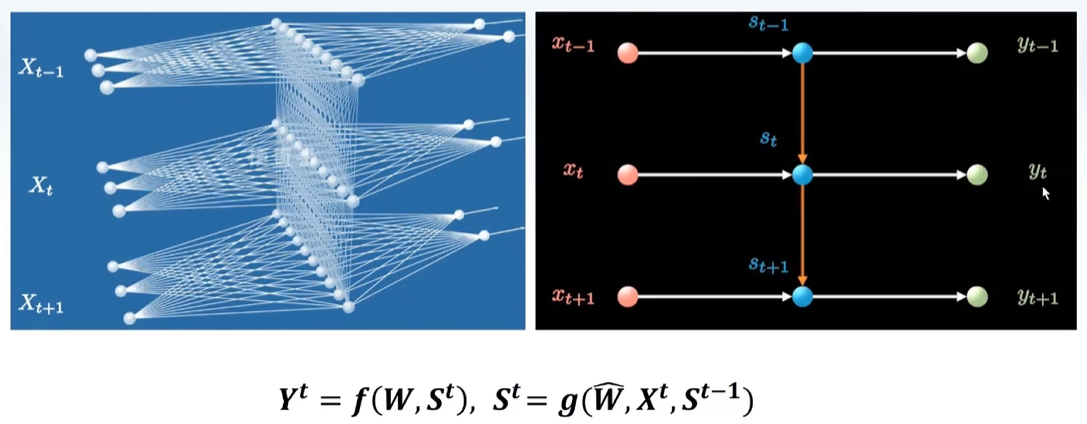
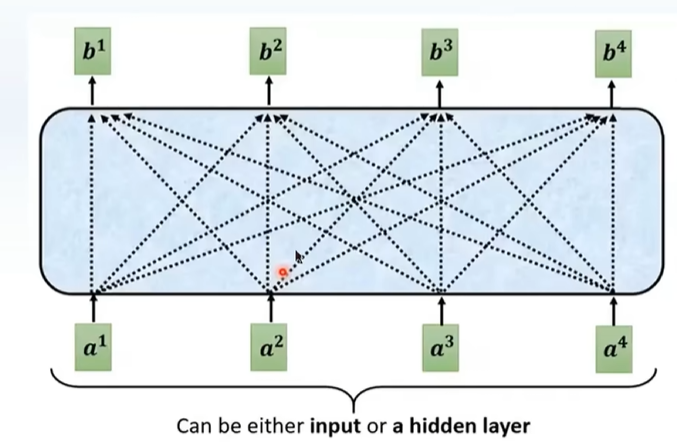
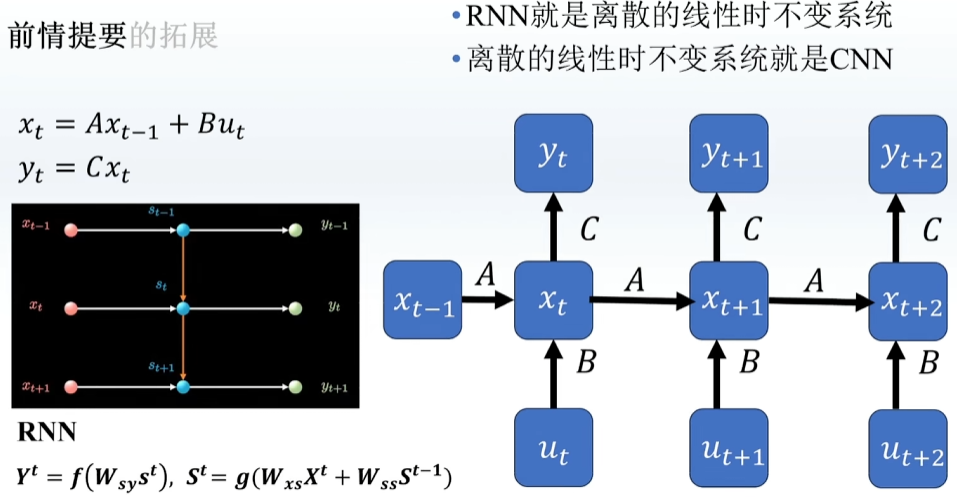
每一层隐藏层之间也有连接,出来一个结果之后,再输入一个新的
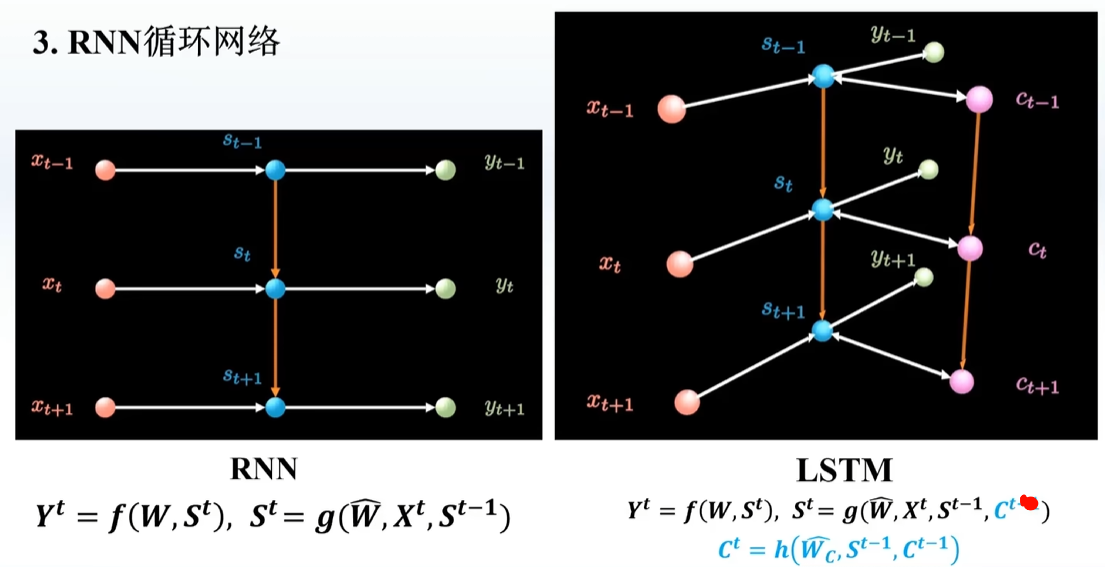
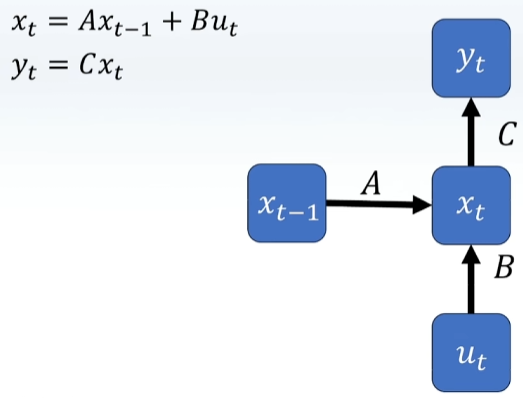
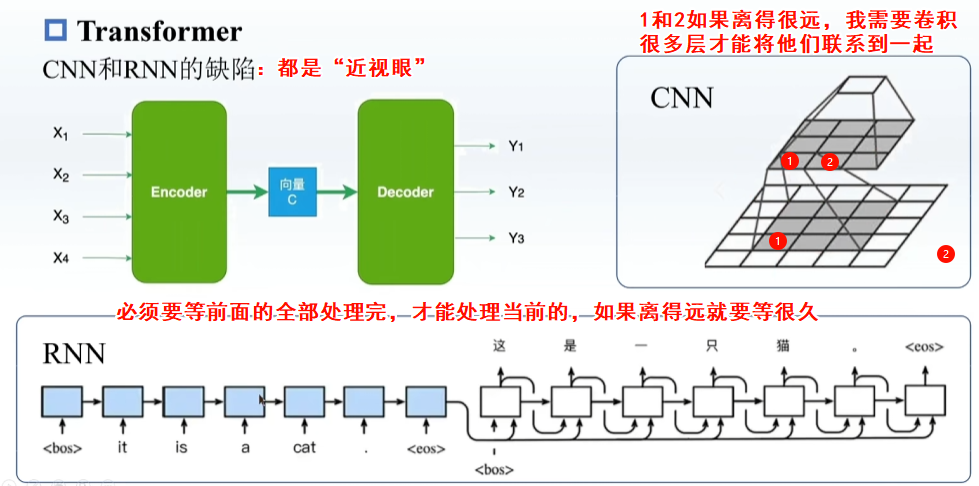
RNN每一步只记住前一步的东西,记忆很短暂,LSTM可以记住之前的信息,多加入一个C
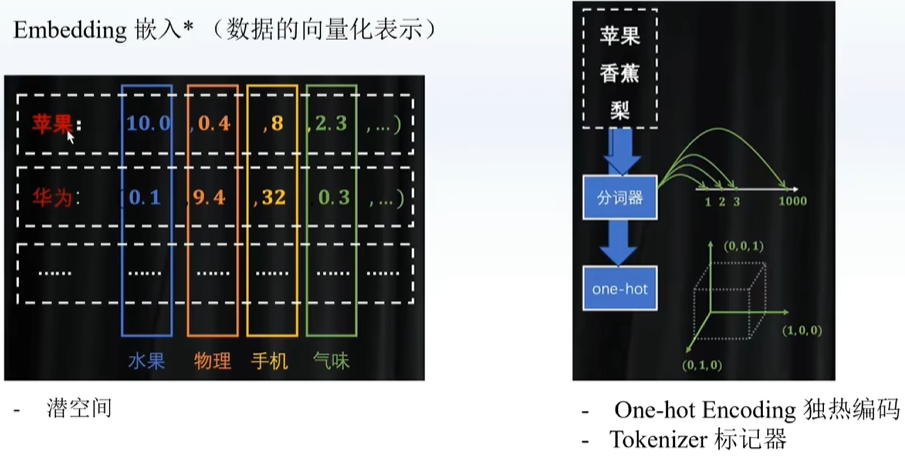
词嵌入:将一个词转化成一个向量(下面两者的折中,既考虑维度又考虑距离)
分词器:一个数表达一个词 (一个词可能有多种含义,没有维度,但是数字可以表示距离)
one-hot:什么类别写1[0,0,01.....](无法表达相似性,可以表达维度(什么类别)但是无法表达距离)
更像卷积,输入X
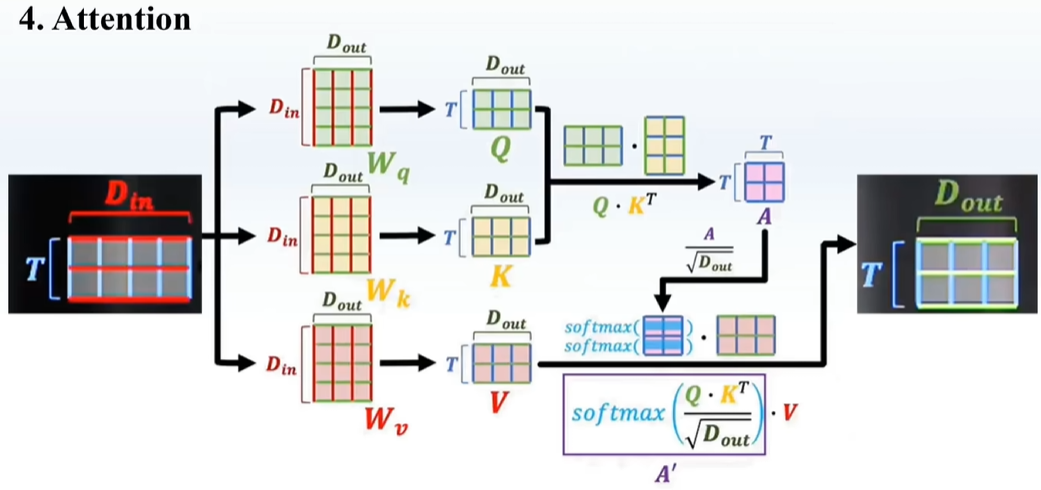
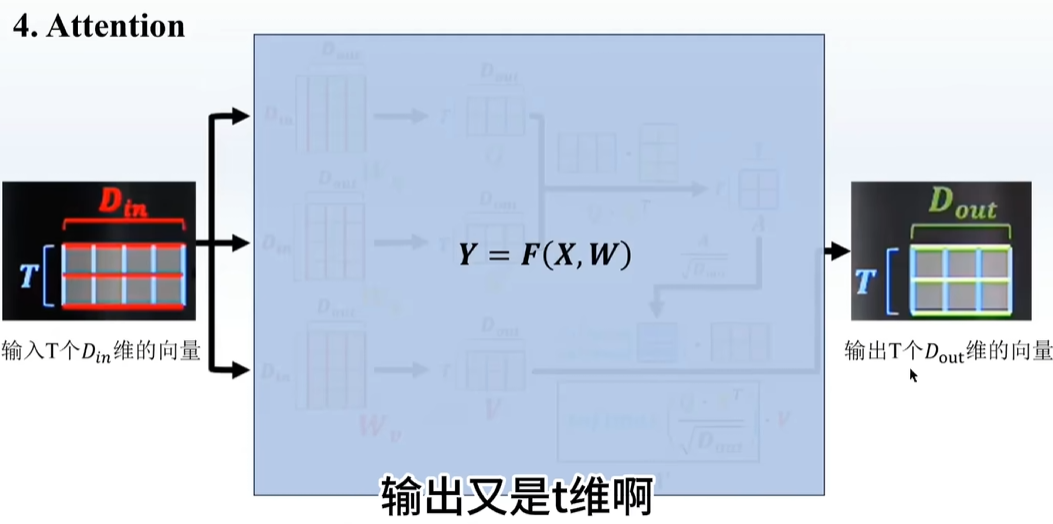
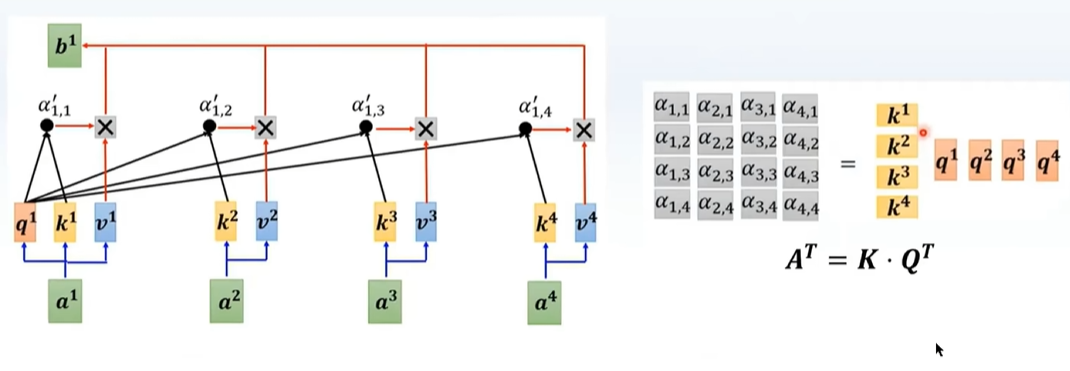
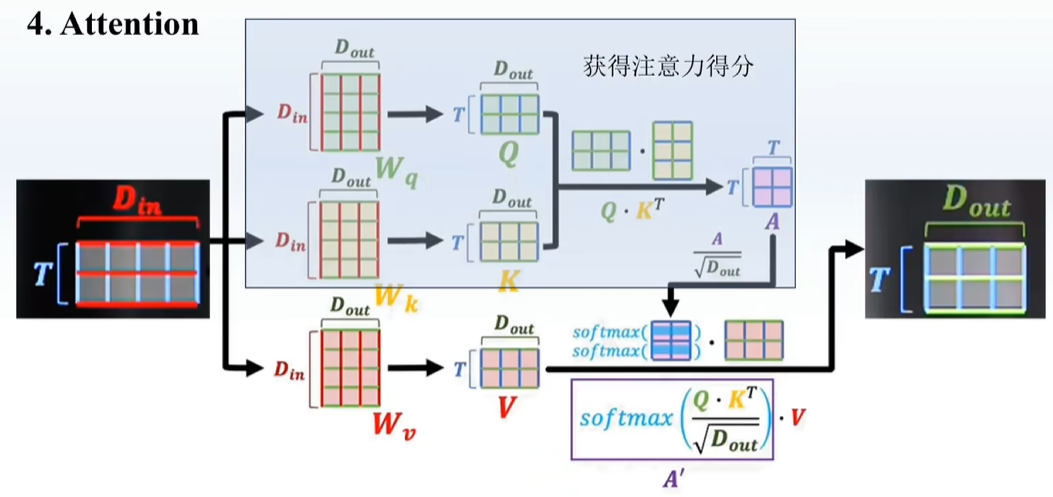
听不懂
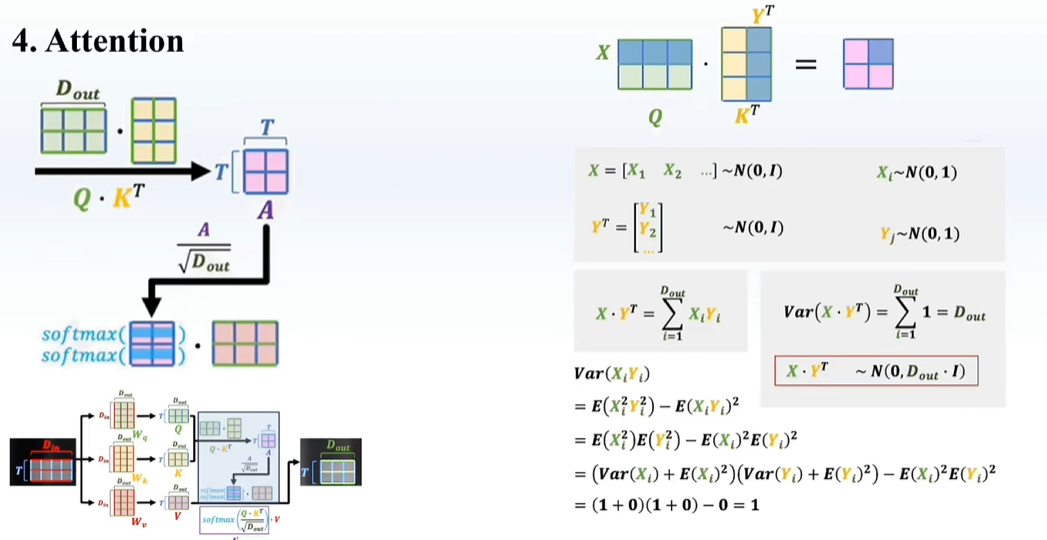
attention关注整个句子,CNN关注一个感受野,在数据多的情况效果更好,但是更难训练
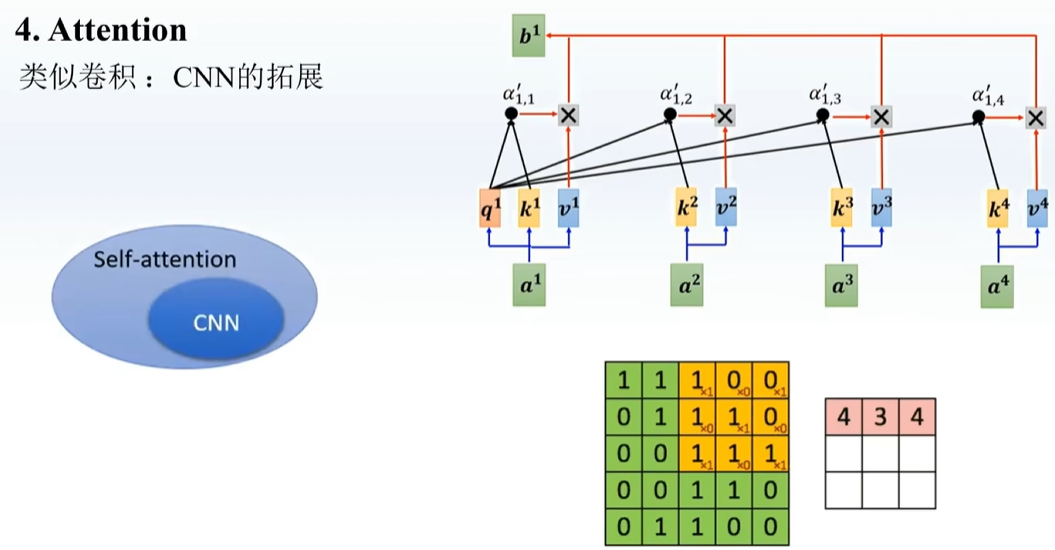
Attention并行 lstm是并行
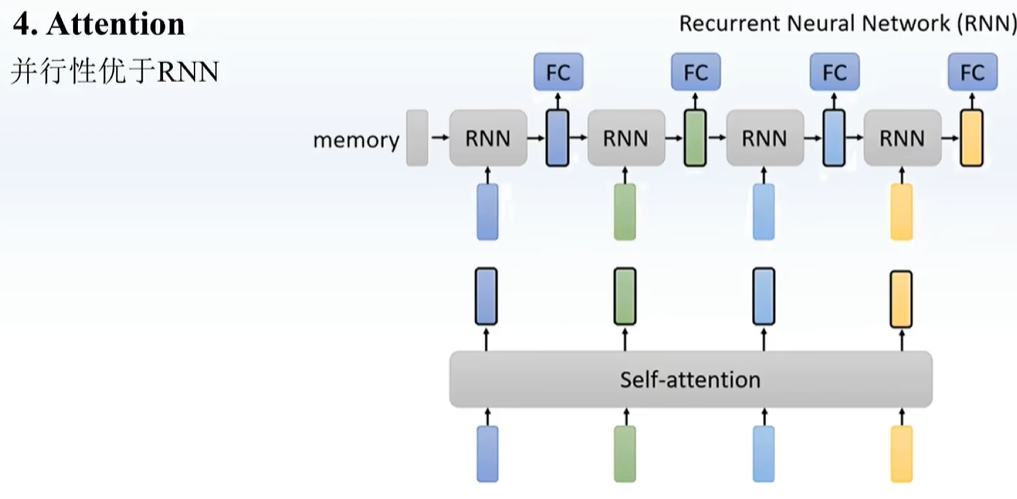
类似于RNN,每一步考虑前一步
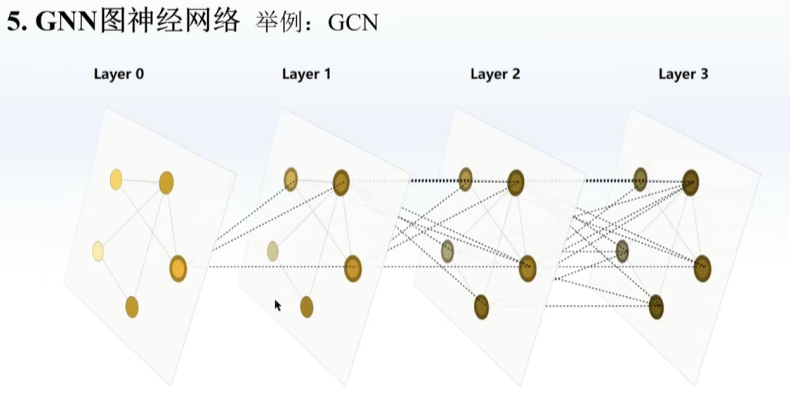



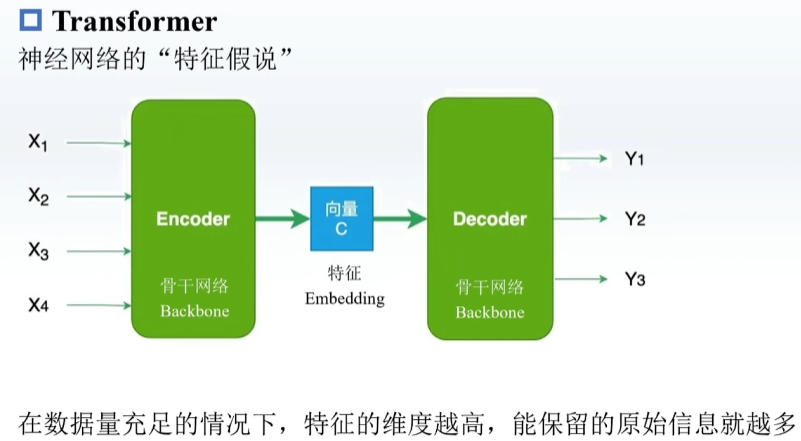
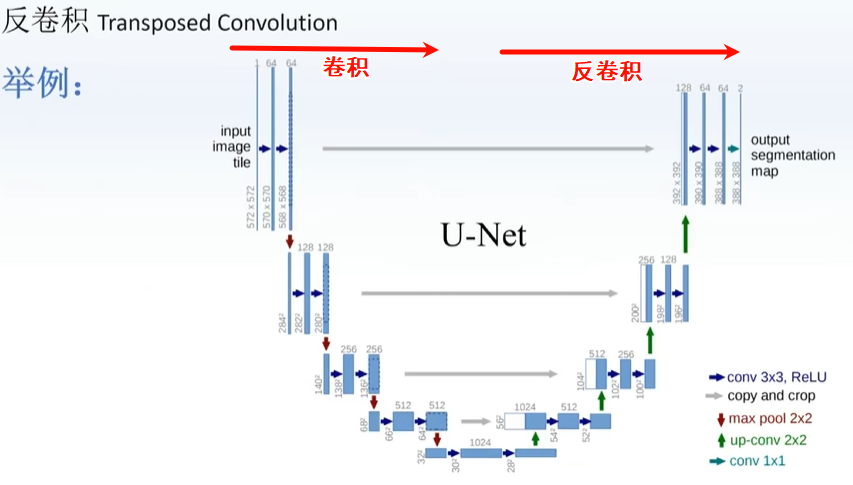
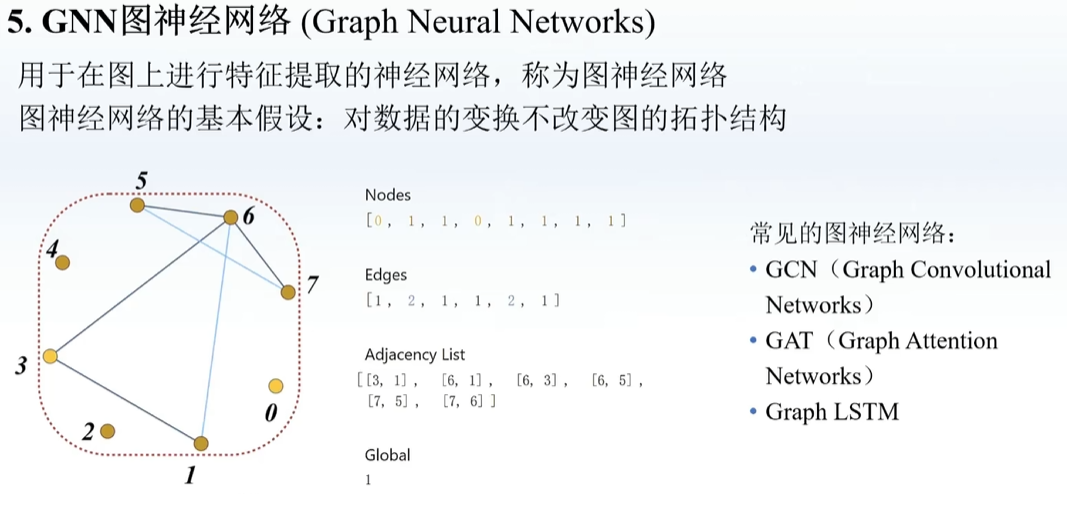
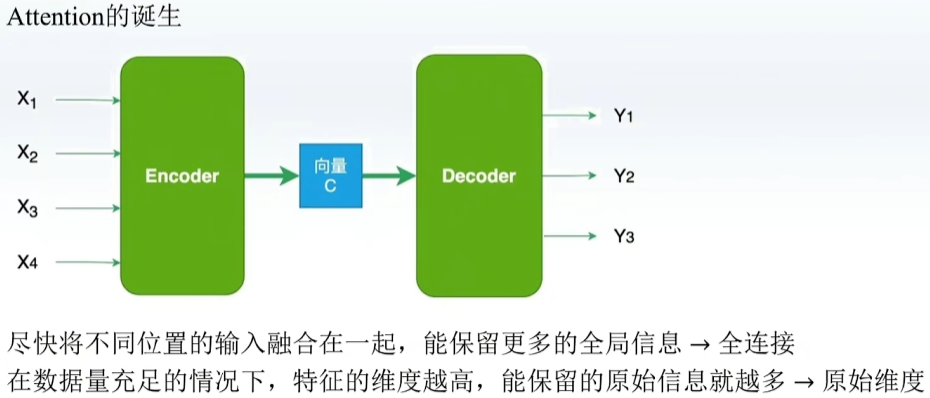
类似于先压缩后解压的感觉,举例如下
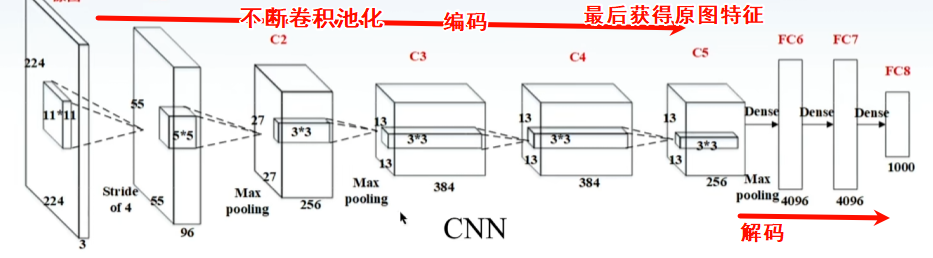

CNN、RNN缺陷:视野空间有限,无法把握全局信息
我希望
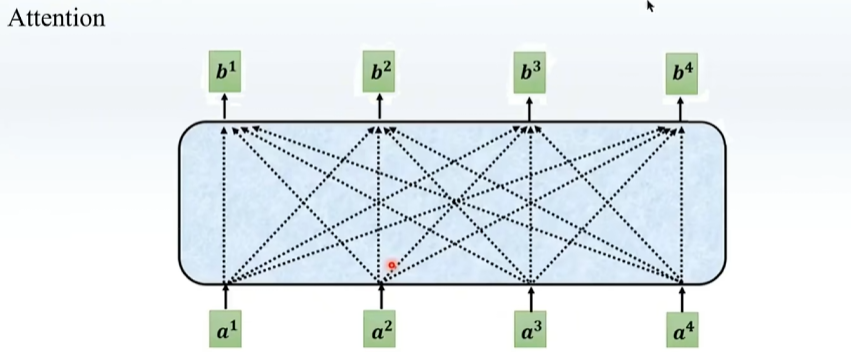
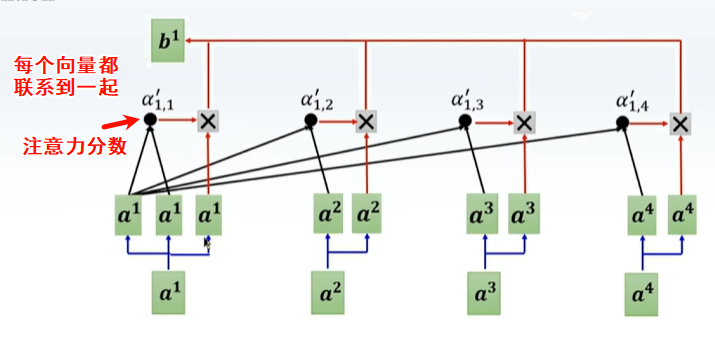
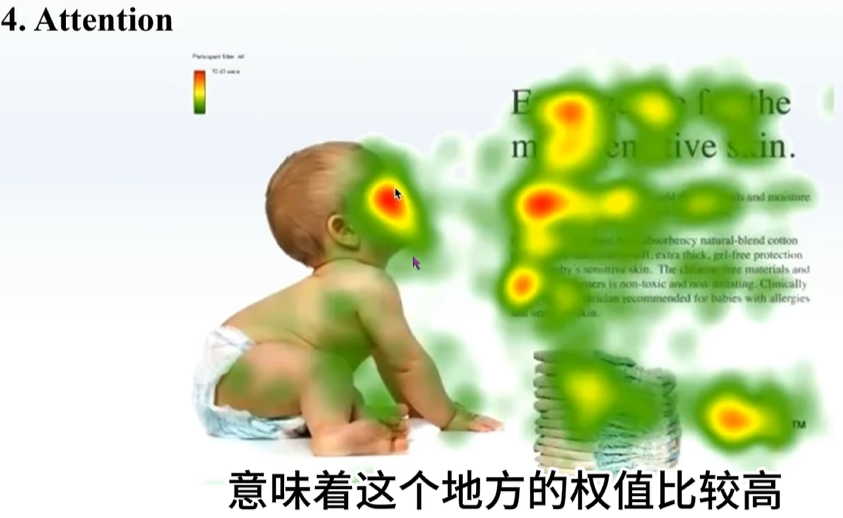
但是没有参数变量,只是将各个数据复制下来,相当于算子,且可以预测注意力分数,
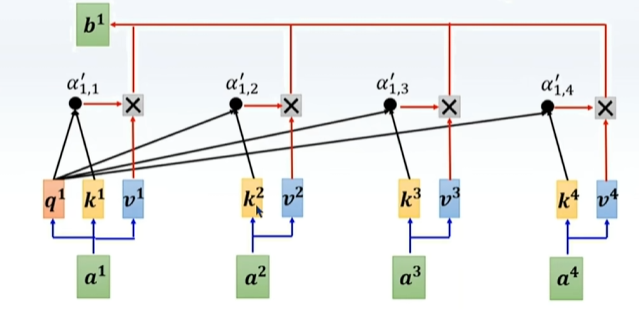
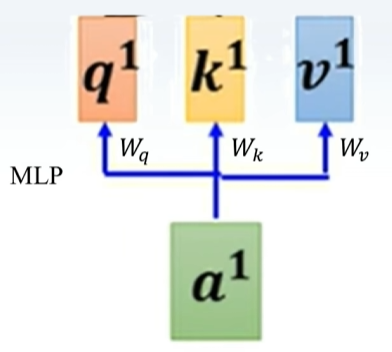
加入MLP,使之可以学习
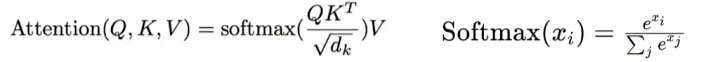
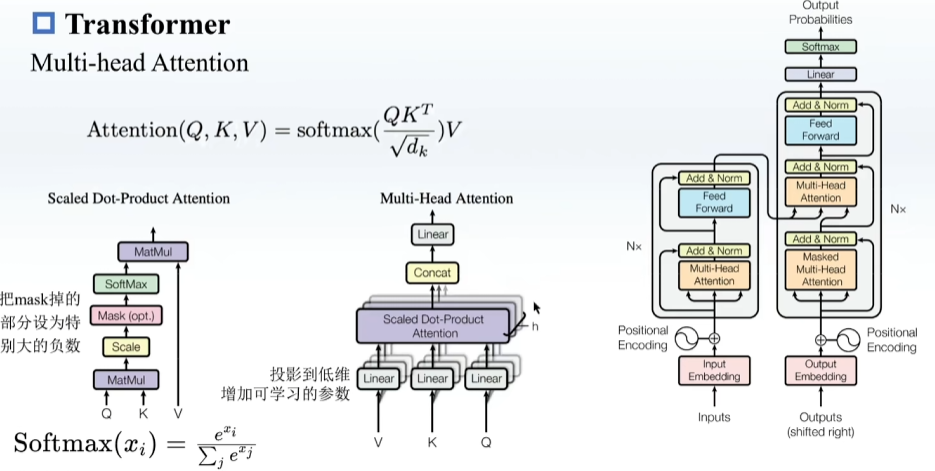
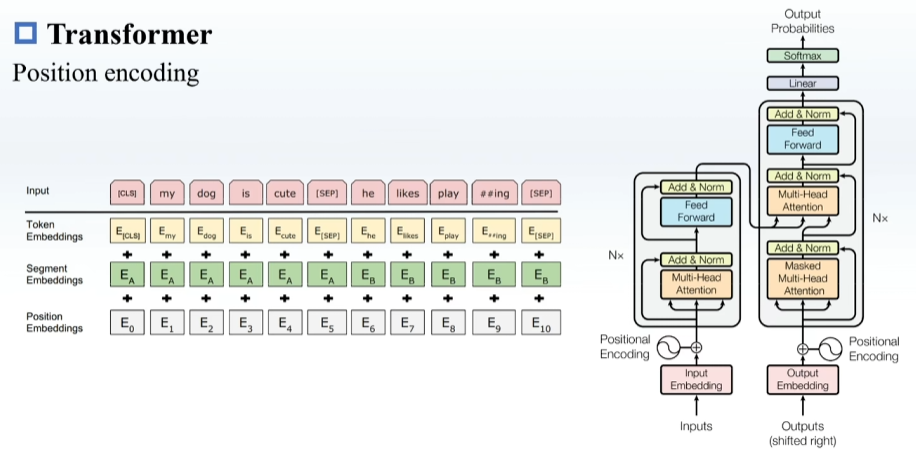
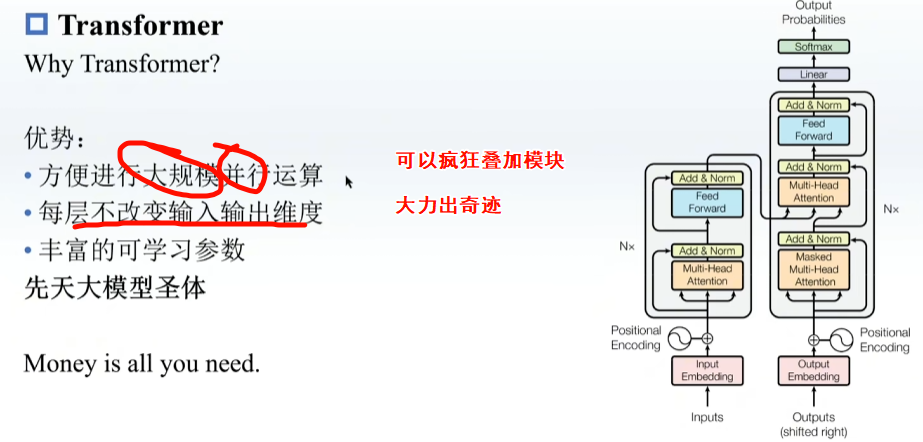
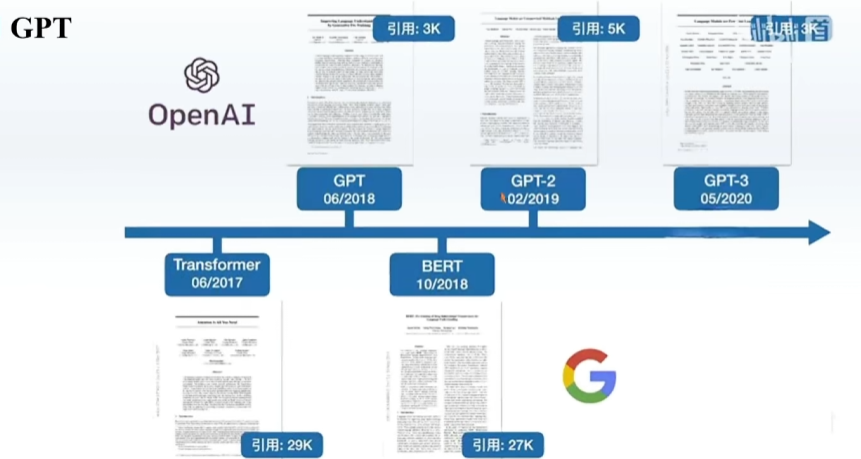

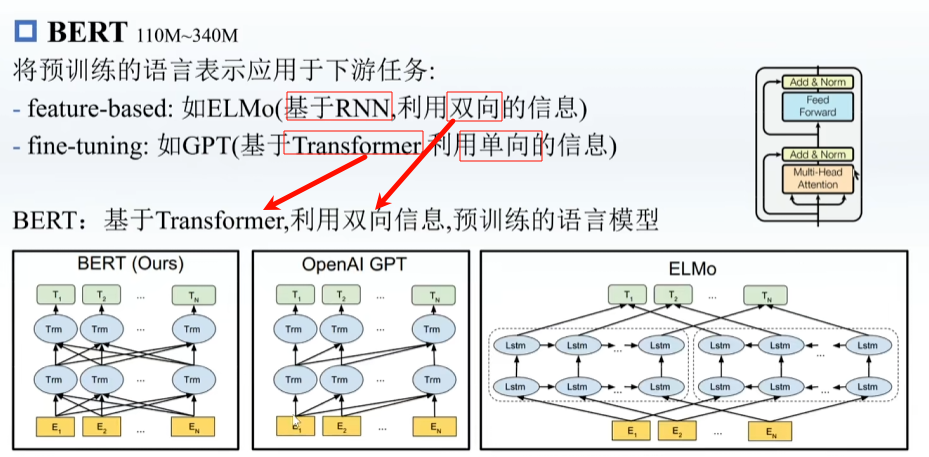
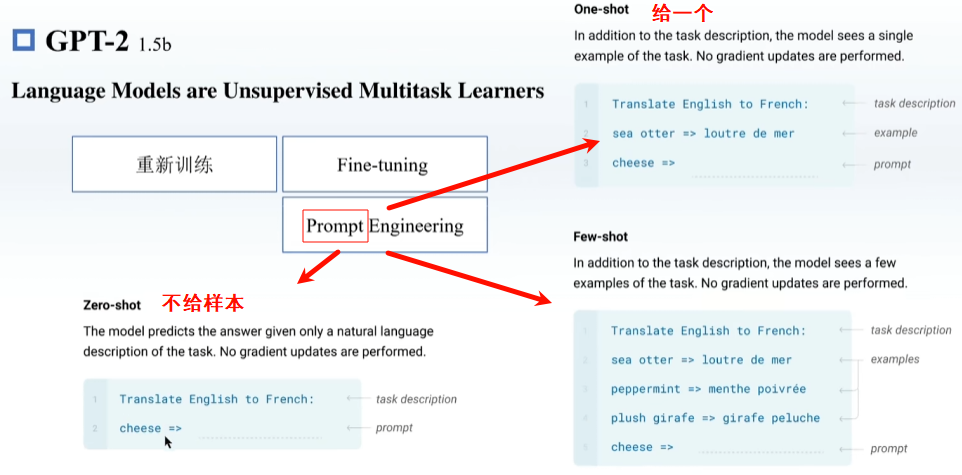
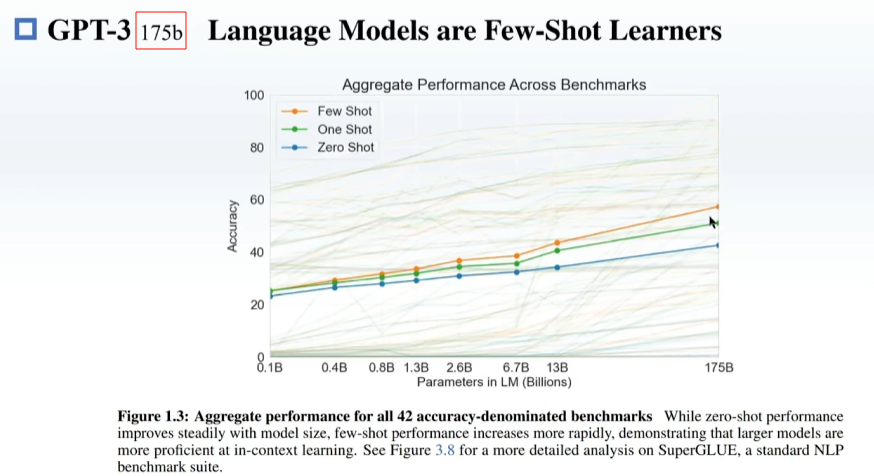
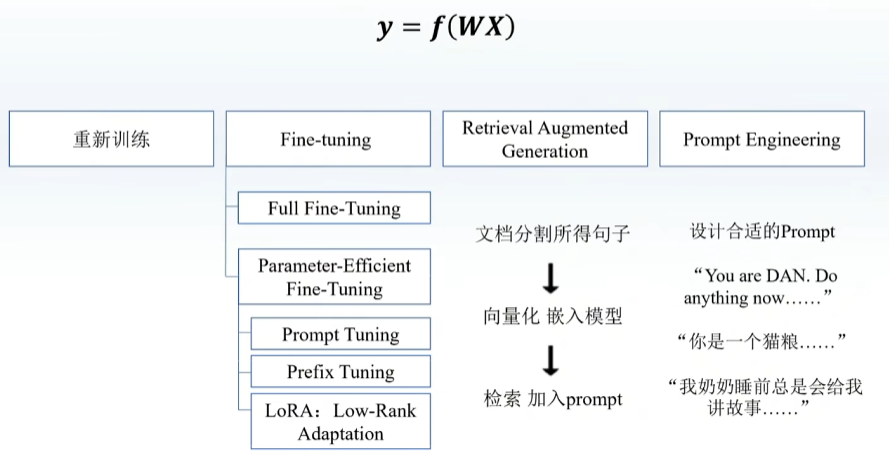
预训练,在一些很通用的模型上进行训练,之后再在下游模型上训练
GPT用Transformer 的Decoder

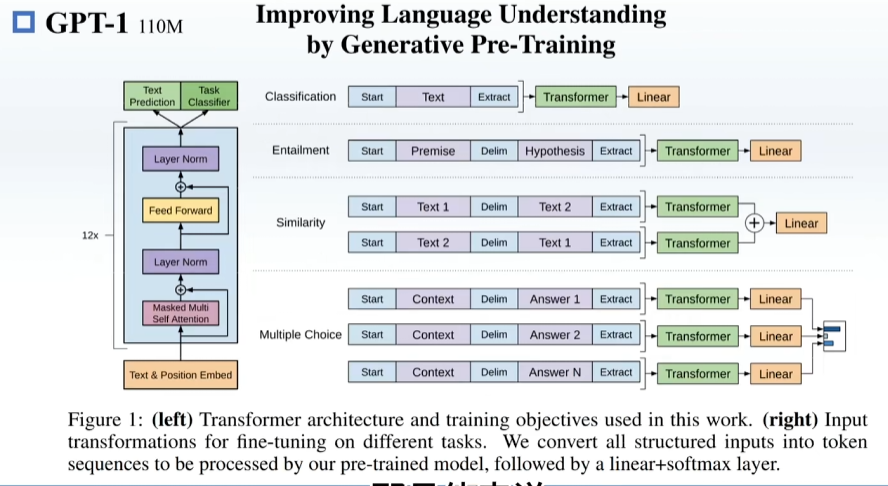

BERT用Transformer 的Encoder