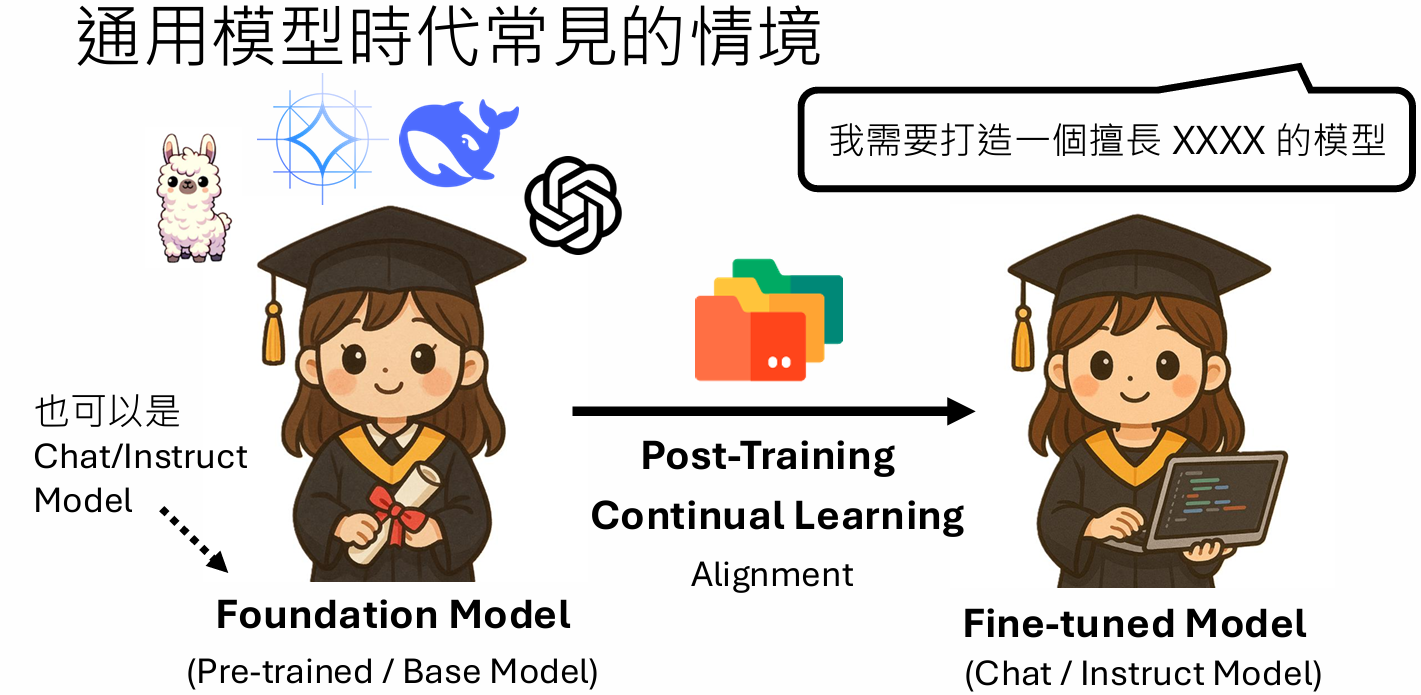
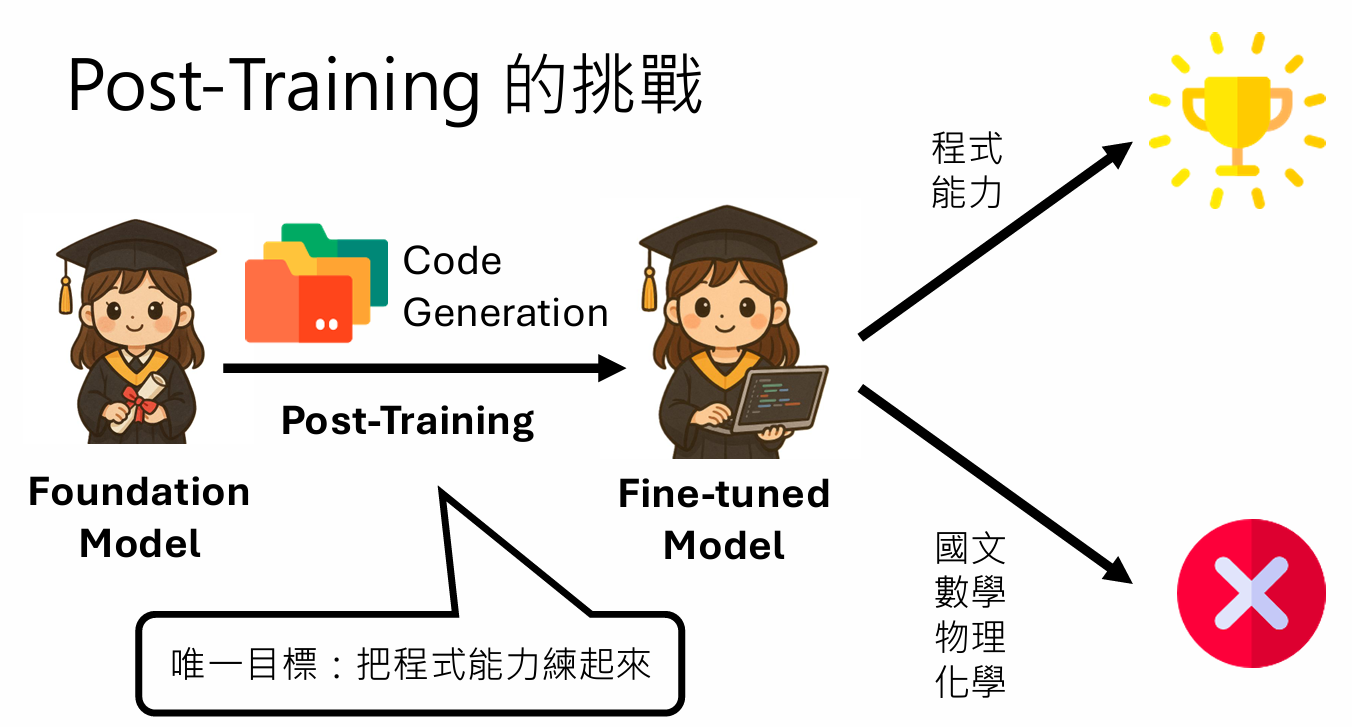
Post-Training & Forgetting
Post-Training 后训练:对已有的大语言模型再给他一些“特定”的训练资料训练,让他更擅长于某种能力。
通才--->专才 也叫continual learning
训练过程依旧是pretrain, SFT, RLHF
但是在做完Post-training之后会发现模型原本的能力会被破坏
例如下面LLaMa-2-chat原本对齐完之后是可以用英文正确回答问题,我们在对他进行中文的后训练之后,他虽然学会了中文,但是他之前对齐alignment的学到的能力却被“遗忘了”



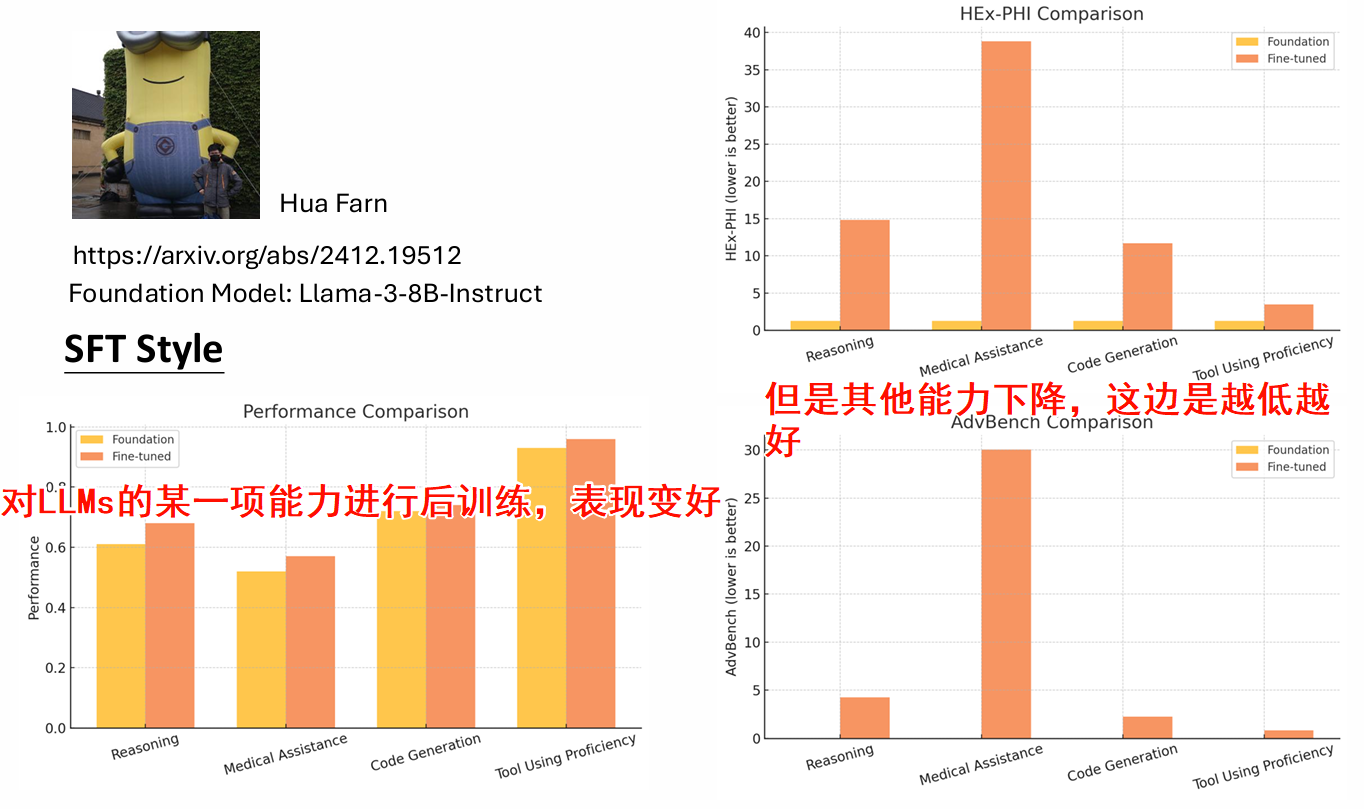
以上就是LLMs的后训练会遇到的Catastrophic Forgetting(灾难性遗忘)

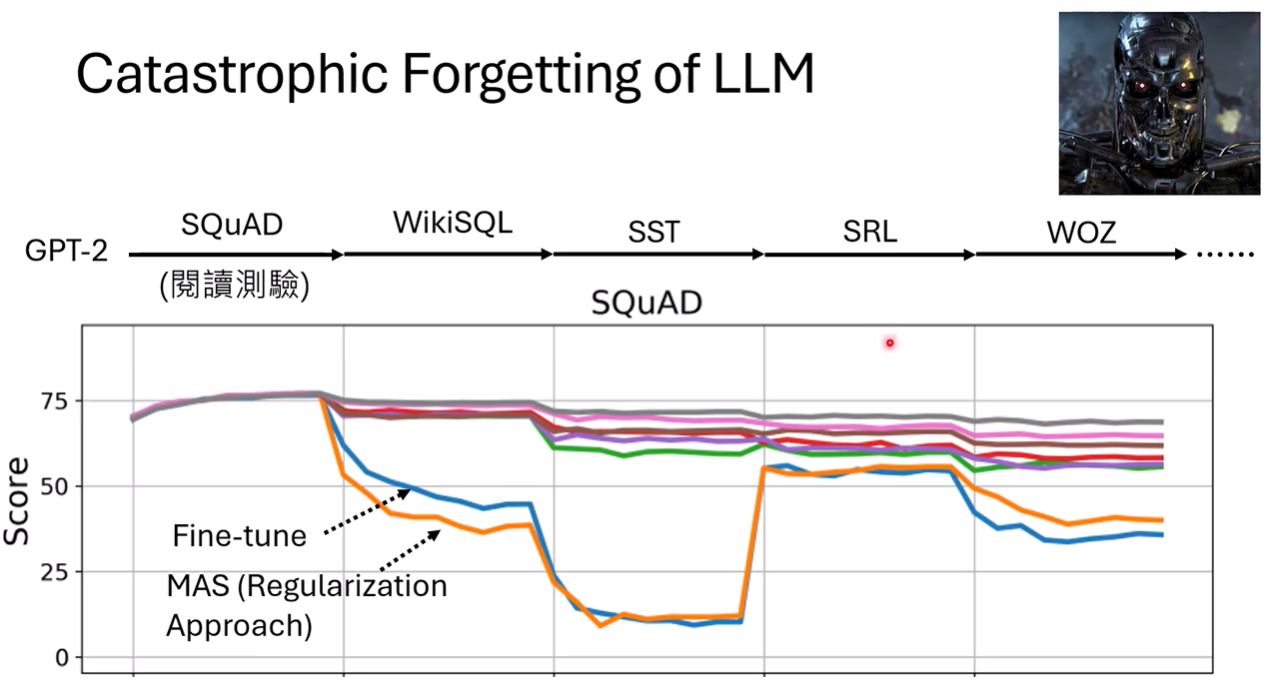
很多论文结果显示:学到越好,忘的越多;学的越少,忘的越少
[2405.09673] LoRA Learns Less and Forgets Less LoRA的r越小,忘的越少
好有梗哈哈哈哈
如何让LLMs不要遗忘呢·
史前时代教GPT2一个阅读测验后能力比较好,接着再让他学习其他的能力,原先阅读测验的能力有时忘的很厉害有时又可以想起来一点点
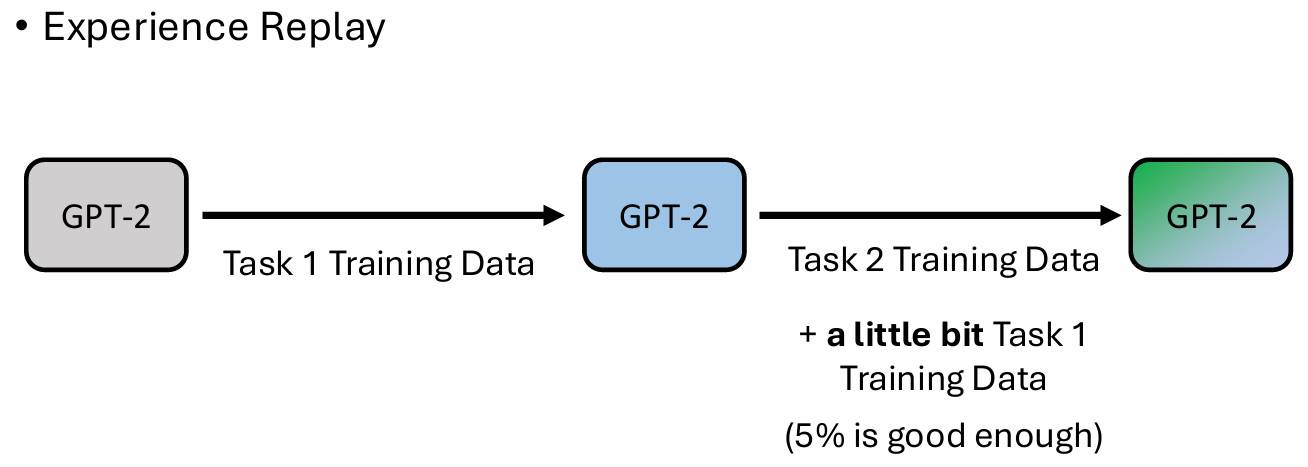
Experience Replay:史前时代发现如果把在每次学习新东西的时候里面再加一点点(百分之五)之前的任务,就不会遗忘
上图中紫色的线就是 Experience Replay 后模型的表现能力
这样感觉遗忘的问题并不难解决,只要每次训练的时候用一点小提示把大模型唤醒就可以。
Wwwwwait!!! 但是目前大模型只会释放出模型而不会释放出训练资料,因此我们根本没有办法在训练的时候加入那百分之五的资料把大模型唤醒
pseudo Experience Replay
[1909.03329] LAMOL: LAnguage MOdeling for Lifelong Language Learning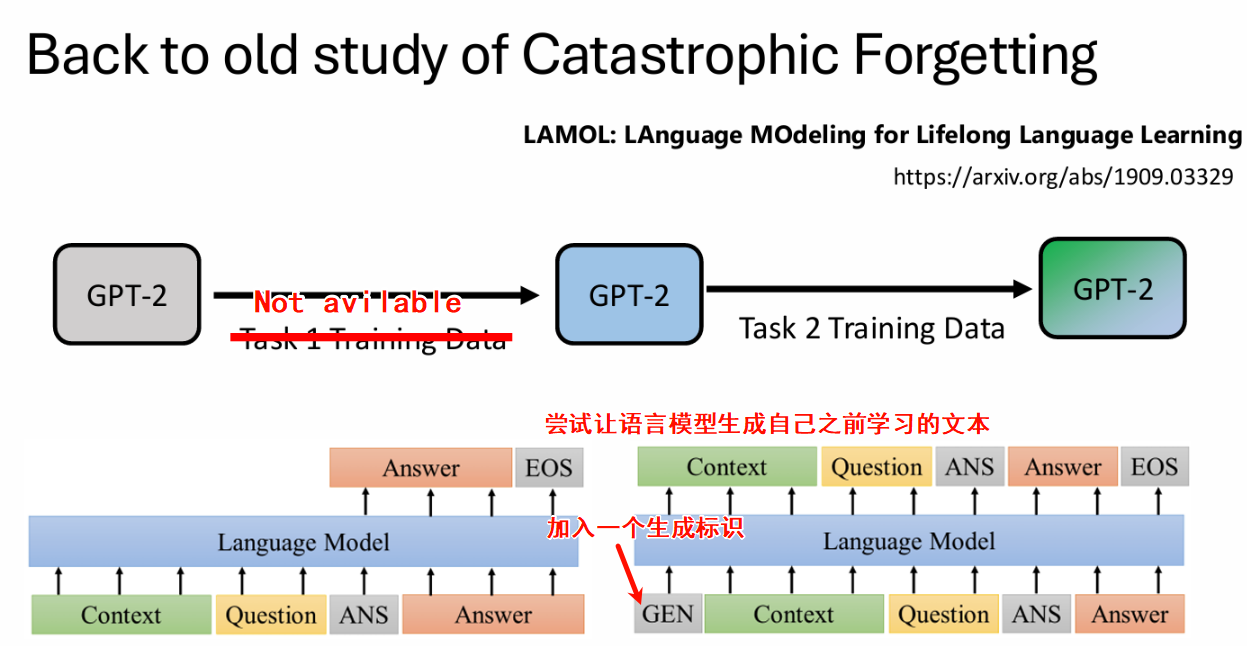 混百分之三的关于safty的资料,让模型safety alignement的能力不要被遗忘[2309.07875] Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions
混百分之三的关于safty的资料,让模型safety alignement的能力不要被遗忘[2309.07875] Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions
训练资料不可获得,让LLama自问自答产生一点他的训练资料[2403.01244] Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal [2406.08464] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
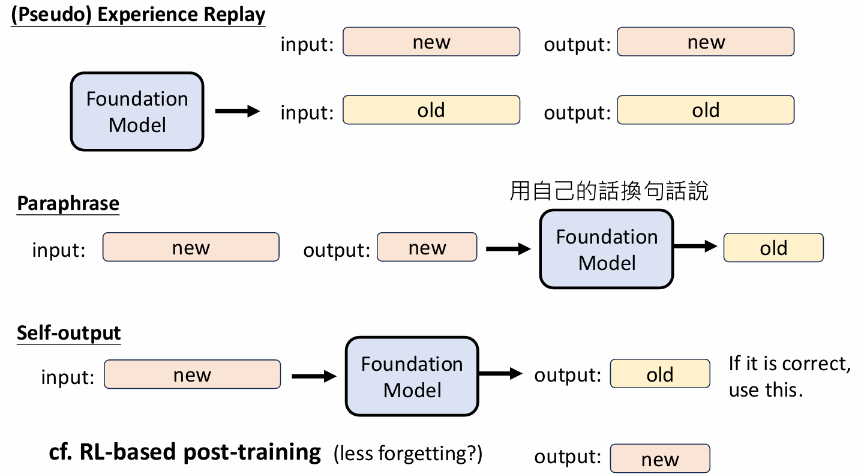
Mega-Pie:该技术让基础模型“自问自答”。先给模型一个
USER:的标识,让它生成一个问题;再将“USER:+ 生成的问题 +ASSISTANT:”作为输入,让它生成答案。这样就凭空创造了高质量的、符合模型自身风格的SFT数据。答案改写(Paraphrasing):不直接使用人类编写的标准答案,而是让基础模型先将其“改写”一遍。用模型自己改写后的,可能跟他之前学习到的东西很像,能取得更好的效果并减少遗忘。
选择性自我排练(Selective Self-Rehearsal):在训练时,先让基础模型尝试回答问题。如果它的答案是正确的(这在数学、编程等可自动验证的领域是可行的),就直接用它自己的正确答案来训练自己。只有当它答错时,才使用人类提供的标准答案。类似于RL[2409.04787] Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
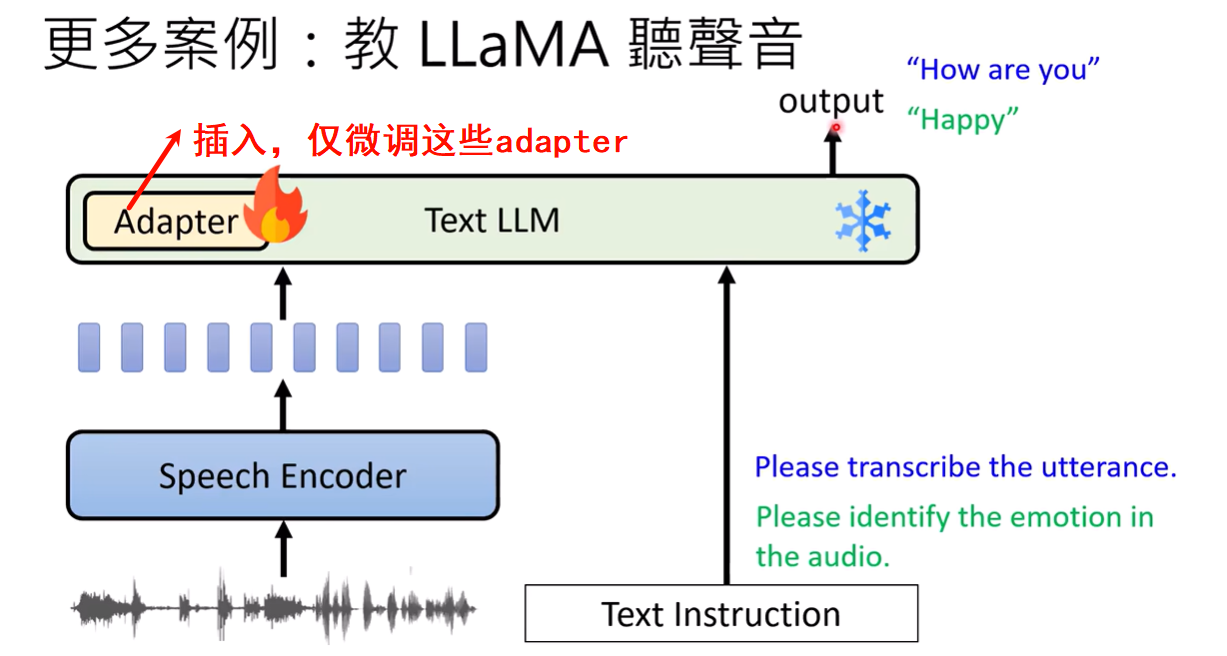
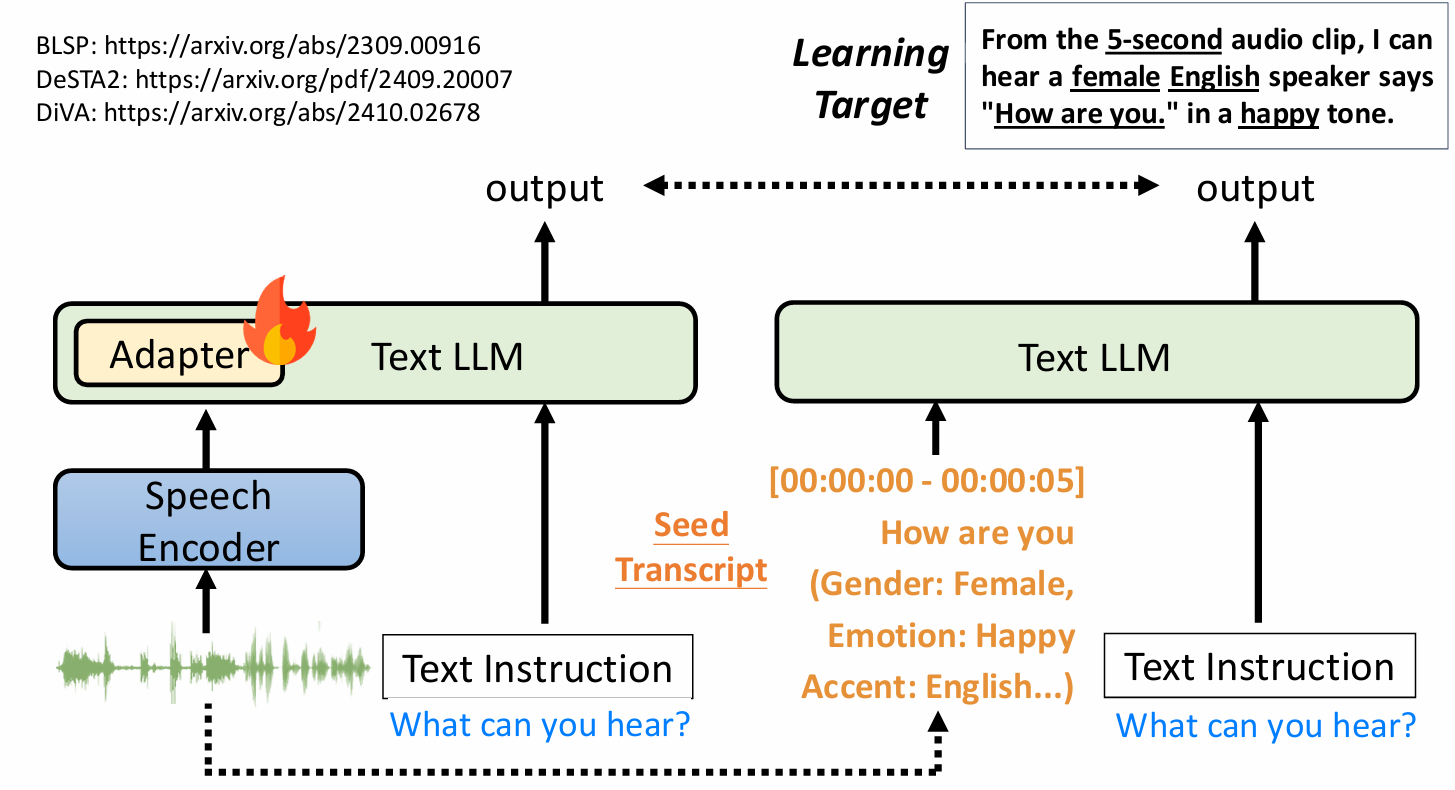
self-output[2402.11192] I Learn Better If You Speak My Language: Understanding the Superior Performance of Fine-Tuning Large Language Models with LLM-Generated Responses发现,用一个(哪怕是不同的)LLM生成的答案来教另一个LLM,效果通常好于用人类编写的答案。这可能是因为LLM之间的“语言范式”更为一致。下面就是一个在训练大模型听语音能力中的具体使用例子:
把语言的的相关信息用文字表示出来,问原始大模型“What can you hear?” 这个LLM就像真的听到了这个语音一样并进行回答,我们把这个回答当作原本要训练的语言模型的目标回答进行训练,会发现遗忘的情况减弱了,就像是训练的时候也加入了之前的一些训练资料一样
感觉像大模型更懂彼此之间的语言
还有一个很直觉的方法,先看一下在fundation model上看一下有哪些token是模型产生几率很低的,然后再接下来的学习生成中就不强求模型考虑这个事情(感觉就像是知道模型在哪些题目上比较弱,就在考试的时候不出这些题,这样模型考的分数就高一点;也可以理解为这个生成的概率时符合他之前生成习惯的;感觉跟之前让他学习自己生成的内容一样,那个是学习以前的经验,这个是没有经验但是告诉他不能做什么)

在计算损失函数时,直接忽略掉这些对模型来说最难的Token。实验表明,在训练中移除约20%最难的Token,不仅不会损害学习效果,反而能提升模型在领域内和领域外的泛化能力,因为它避免了对模型进行“强制教学”。

总结
在做post-training想让模型学到某一个具体的能力时,除了让看模型在这个能力上是否表现好,也要注意模型是否遗忘掉很多本该会的东西;目前对于遗忘这个问题比较好的解决方案就是用模型自己生成(就是有一些他之前学习到的经验,提醒他不要忘记)的话来做后训练